[ad_1]
You’ve finalized the development of your twitter-killer application. You heard of NoSQL databases and resolved to use ScyllaDB for its sub-millisecond writes and high availability. The application appears also wonderful! But then, you get an e-mail from your colleague telling you there are troubles with the load assessments.
 ScyllaDB Checking Dashboard: CQL
ScyllaDB Checking Dashboard: CQL
The previously mentioned screenshot is the ScyllaDB Checking dashboard, a lot more especially from the Scylla CQL dashboard. We can clearly see purple gages indicating there are a few troubles in the app.
How can you more enhance your code to face hundreds of thousands of operations? Listed here are 5 approaches to get the most out of your CQL queries.
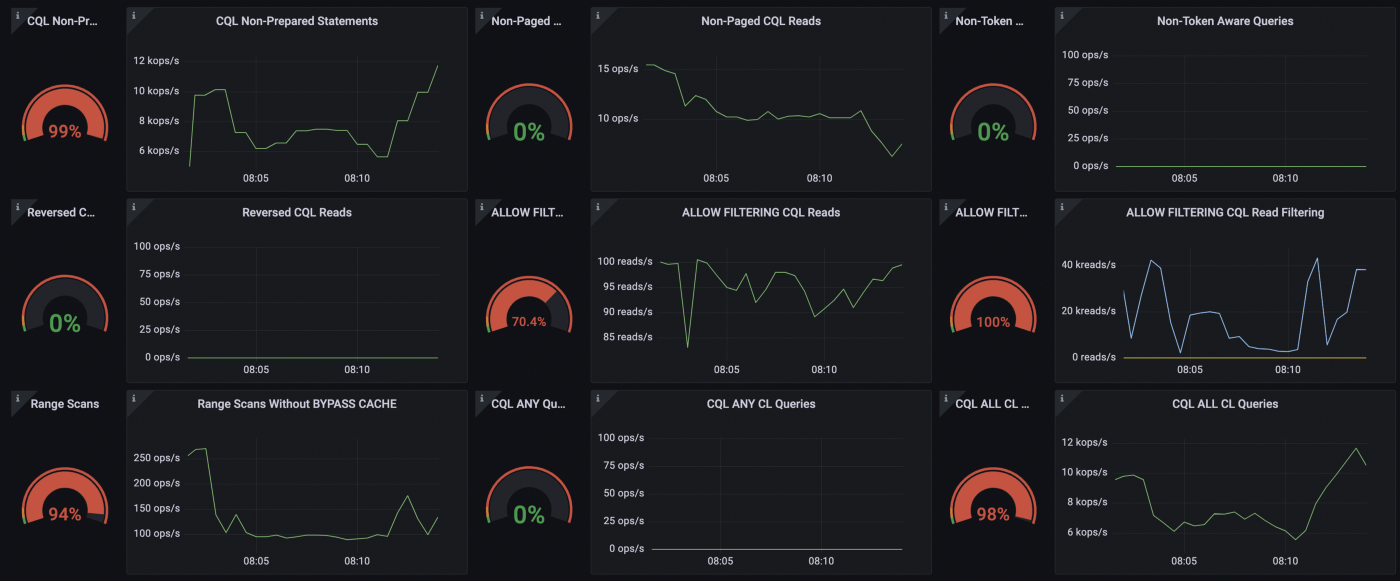
1. Prepare Your Statements
We can see from the ScyllaDB CQL Dashboard that 9
 ScyllaDB CQL Dashboard Non-Geared up Statements
ScyllaDB CQL Dashboard Non-Geared up Statements
You can run a query applying the execute purpose like so:
rows = session.execute(‘SELECT identify, age, email FROM users’)
for person_row in rows:
print person_row.name, user_row.age, consumer_row.emailThe earlier mentioned question is an illustration of a Very simple Statement. When executed, ScyllaDB will parse the query string all over again, with no the use of a cache. This is inefficient if you operate the similar queries usually.

If you typically execute the identical query, contemplate utilizing Ready Statements as a substitute.
user_lookup_stmt = session.put together(“SELECT * FROM consumers The place user_id=?”)consumers = []
for person_id in user_ids_to_query:
consumer = session.execute(consumer_lookup_stmt, [user_id])
customers.append(user)When you get ready the statement, ScyllaDB will parse the query string, cache the outcome and return a exclusive identifier. When you execute the well prepared assertion, the driver will only deliver the identifier, which will allow skipping the parsing section. Also, you are certain your query will be executed by the node holding the information.

Phase 1: Parse question and return statement id

Stage 2: Send out id and values
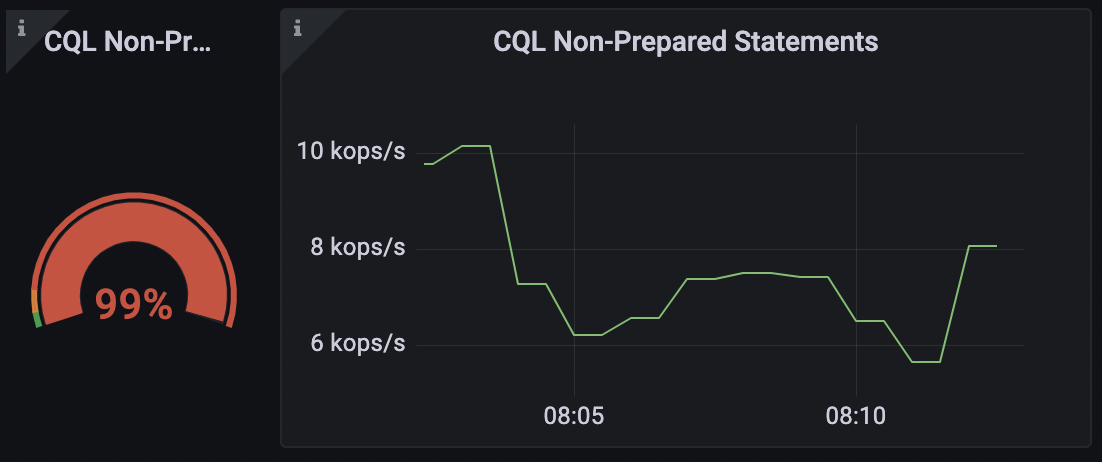
2. Web page Your Queries
We can observe from the graph underneath that only a tiny fraction of my queries are non-paged. On the other hand, if we think about the actuality that each query triggers the scan of an total desk and that the shopper may well not need to have the whole data, we can realize how this is not successful.
ScyllaDB Dashboard Non-Paged CQL Reads
This a person could possibly seem noticeable. If your people question an complete table on a regular foundation, paging could enhance latency tremendously. To do so, you can include the fetch_dimension argument to the assertion.
question = "Decide on * FROM customers"
assertion = SimpleStatement(question, fetch_dimension=10)
for user_row in session.execute(statement):
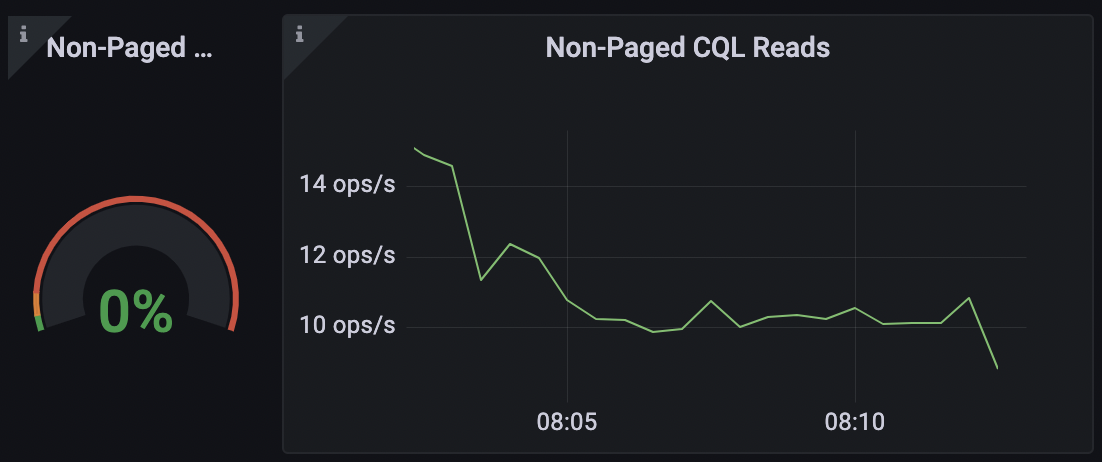
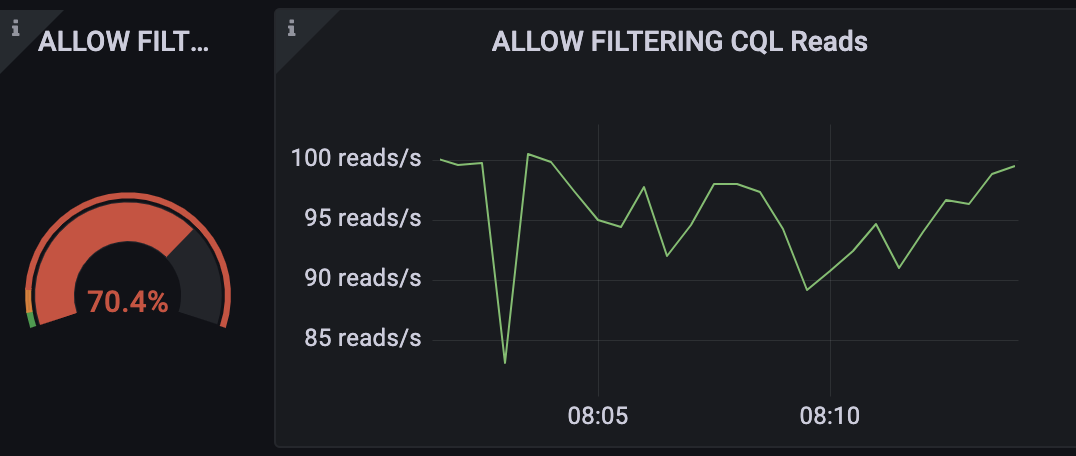
approach_consumer(consumer_row)3. Keep away from Let Filtering
The down below query selects all consumers with a specific identify.
Let us see what the previously mentioned does in far more detail.
From the dashboard, we can see that we only have about 100 reads for each 2nd, which in theory can be viewed as negligible.
Let FILTERING CQL
Nevertheless, the question triggers a scan of the total table. This indicates that the query reads the entire users’ desk just to return a number of, which is inefficient.
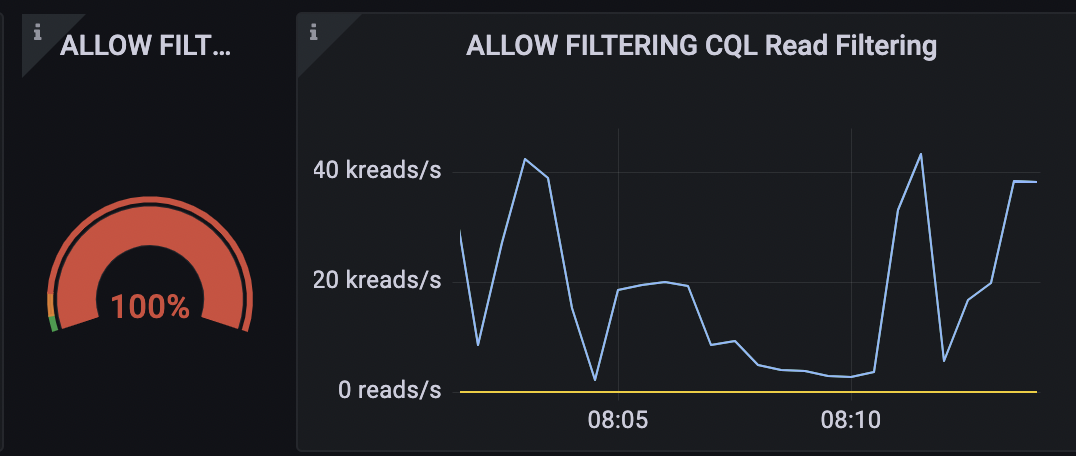
Simply because of the way ScyllaDB is made, it is considerably a lot more successful to use an index for lookups. As a result, your question will normally find the node holding the details without scanning the complete table.
If you sense that is not ample, you may think about revisiting your schema.
4. Bypass Cache
For reduced latency applications, ScyllaDB appears to be like for the final result of your question in the cache very first. In scenario the knowledge is not existing in the cache, the database will browse from the disk. We use BYPASS CACHE to stay clear of pointless lookups in the cache and get the information straight from the disk.
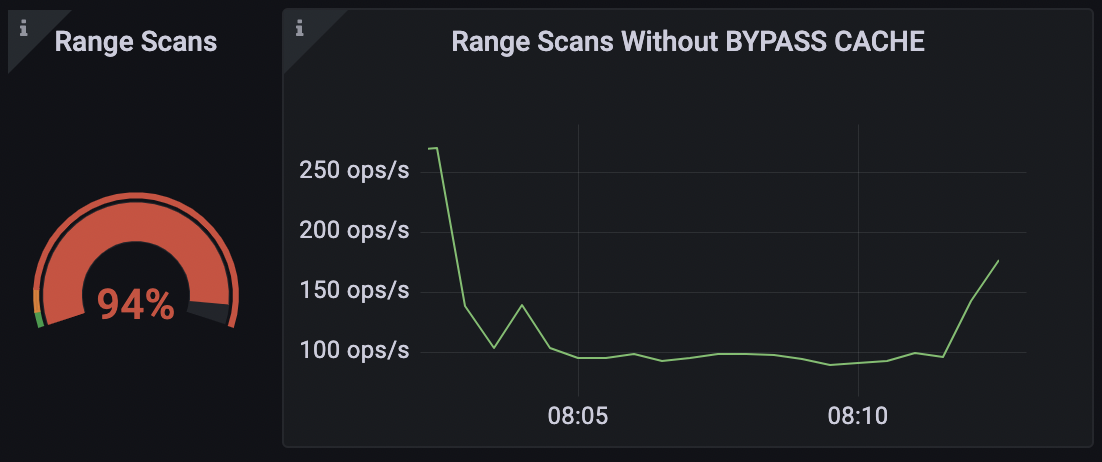
ScyllaDB CQL Dashboard Assortment Scans without BYPASS CACHE
You can use BYPASS CACHE for scarce variety scans to tell the databases that the info is unlikely to be in memory and require to be fetched directly from the disk instead. This will keep away from an avoidable lookup in the cache.
Pick * FROM end users BYPASS CACHE
Find identify, occupation FROM people Exactly where userid IN (199, 200, 207) BYPASS CACHE
Select * FROM consumers Wherever birth_12 months = 1981 AND state = 'US' Let FILTERING BYPASS CACHE5. Use CL=QUORUM
CL stands for Regularity Degree. To much better comprehend what it is, let’s overview the journey of an INSERT query.
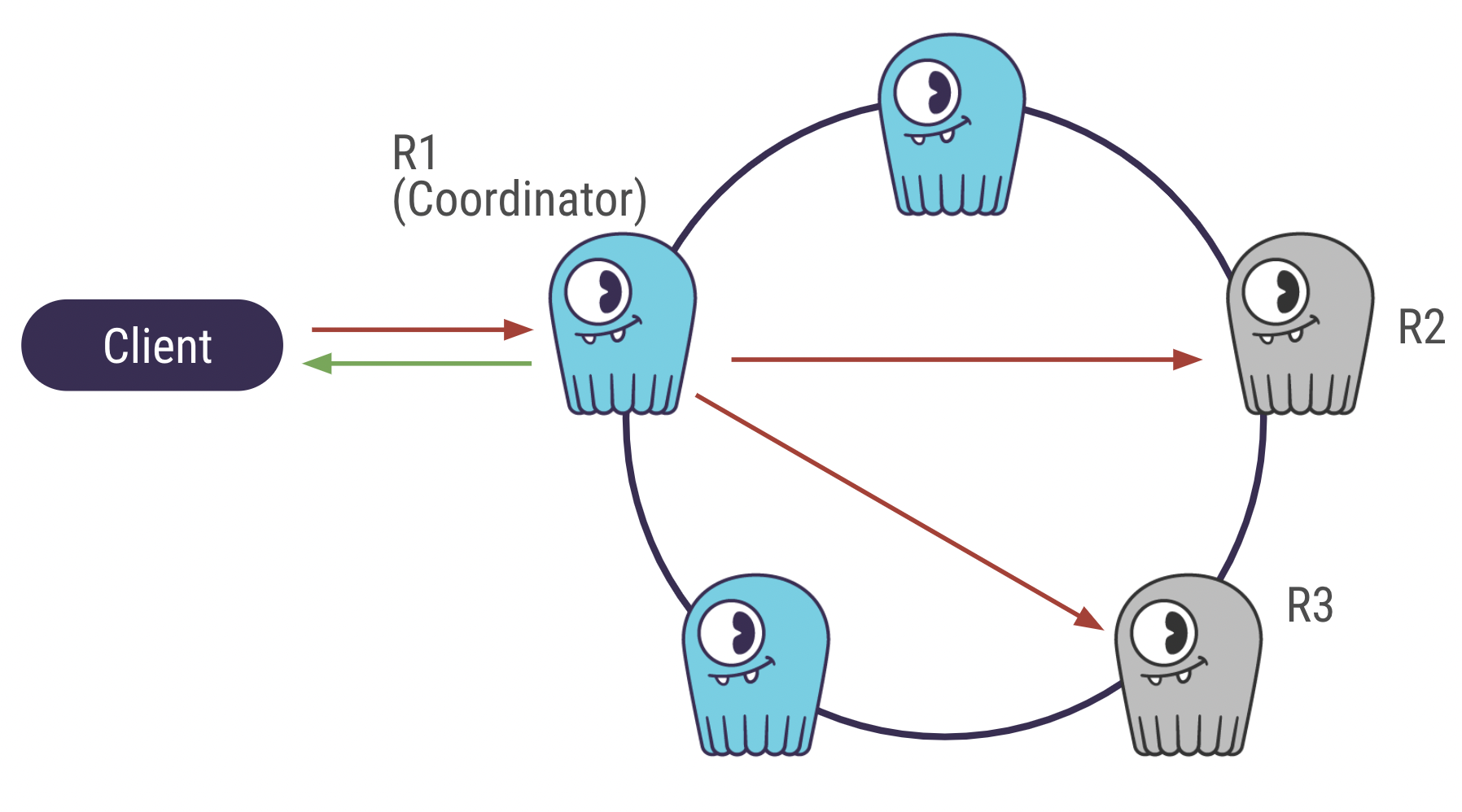
ScyllaDB is a dispersed databases. The cluster is fashioned by a group of nodes (or equipment) that communicate with each other. When the customer sends an insert query, it is 1st sent to a random node (the coordinator) that will pass the data to other nodes to save copies of it. The number of nodes the details is copied to is identified as the Replication Element.
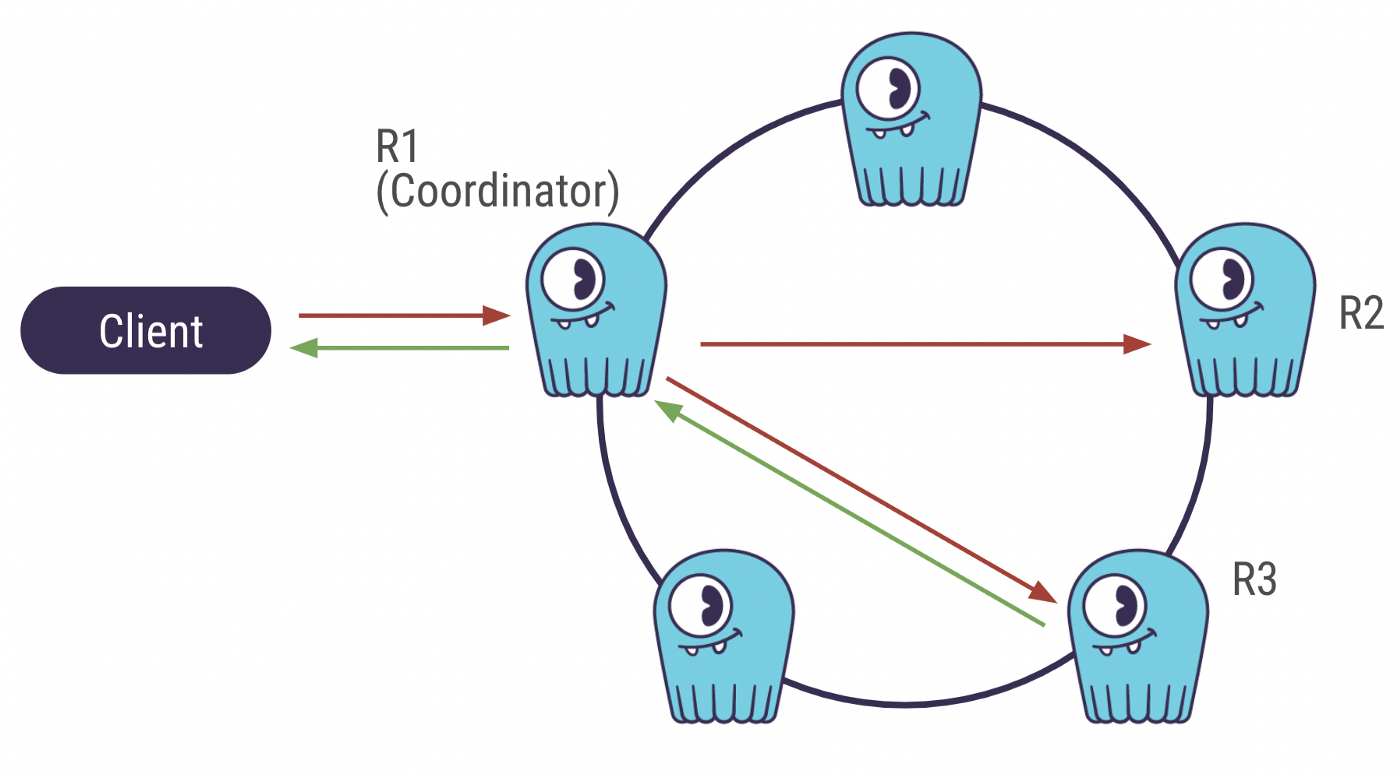
ScyllaDB cluster with Replication Element = 3 and Consistency Degree = Quorum
QUORUM: it delivers better availability than A single and better latency than ALL.
Although the shopper awaits the database’s reaction, the coordinator also demands a reaction from the nodes replicating the knowledge. The number of nodes the coordinator waits for is named the Regularity Degree.
Let us now get back to QUORUM. QUORUM signifies that the coordinator requires the greater part of the nodes to send a reaction ahead of it sends alone a reaction to the customer. The majority is (Replication Factor / 2 )+ 1 . In the above situation, it would 2.
Why should you use QUORUM? Simply because it delivers better availability than One particular and much better latency than ALL.
With CL=Just one, the coordinator sends a reaction to the consumer as speedy as it inserts the knowledge, without having ready for other nodes. In the circumstance that the nodes are down, the knowledge is not replicated and as a result not remarkably out there.
With CL=ALL, the coordinator requirements a response of all nodes in order to respond to the shopper, which improves latency.
 |
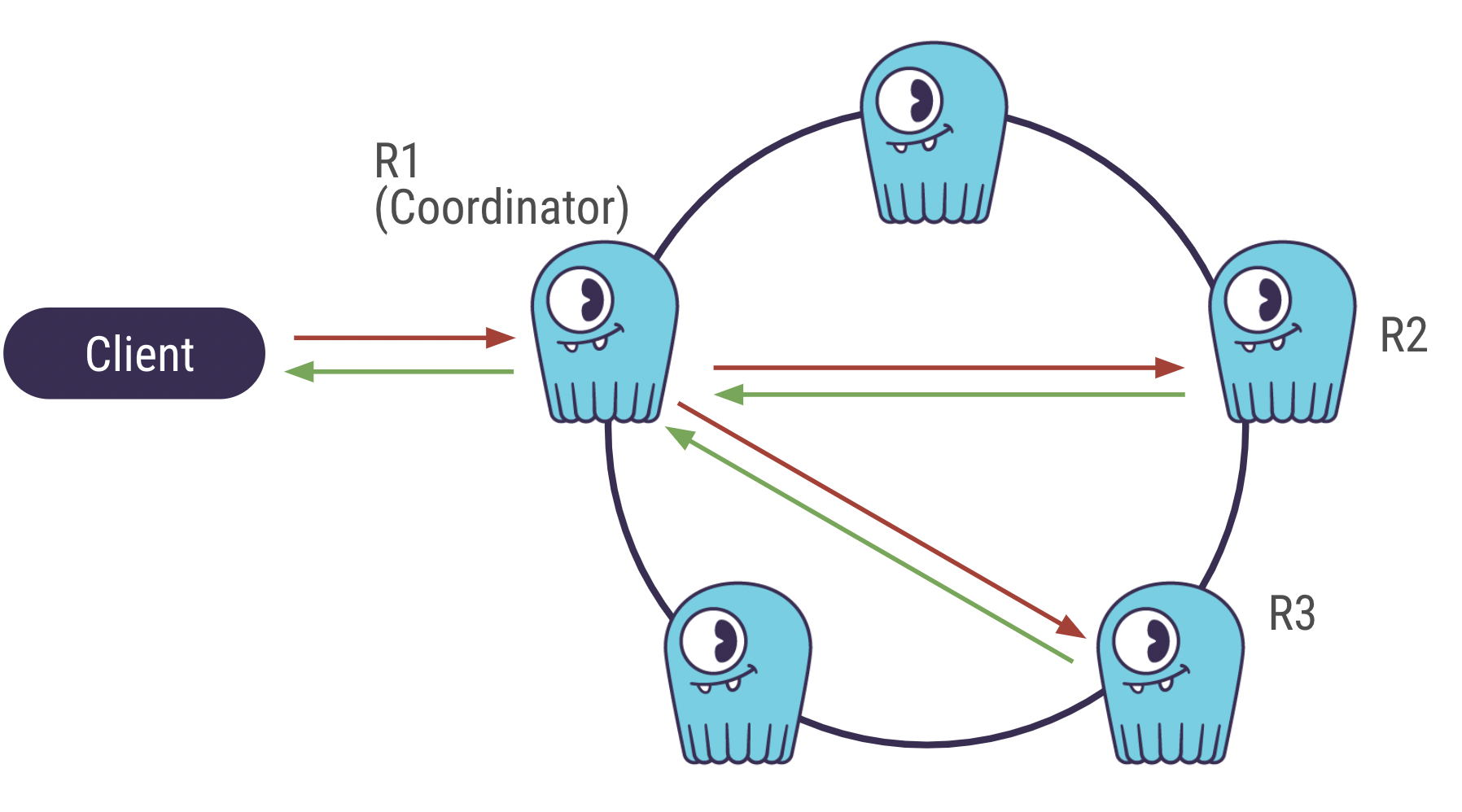 |
Consistency Degree Just one (remaining) vs ALL (right)
Summary
An application that performs well in progress might confront a lot more issues in creation. The ScyllaDB Checking Dashboard describes the health and fitness of your cluster’s nodes and provides you a good sign of the quality of your CQL queries and how they perform at scale. Contemplate working with it at an early stage, for growth or screening, to capture possible issues in your code and take care of them ahead of they ever get to your consumers.

[ad_2]