[ad_1]
20 many years in the past, your data warehouse probably wouldn’t have been voted hottest technologies on the block. These bastions of the place of work basement ended up extended related with siloed facts workflows, on-premises computing clusters, and a restricted set of enterprise-relevant duties (i.e., processing payroll, and storing internal files).
Now, with the rise of information-driven analytics, cross-functional knowledge groups, and most importantly, the cloud, the phrase “cloud details warehouse” is practically analogous to agility and innovation.
In many means, the cloud helps make info less difficult to manage, additional obtainable to a broader wide variety of customers, and considerably more rapidly to course of action. Providers virtually cannot use info in a significant way without having leveraging a cloud data warehousing answer (or two or three… or more).
When it will come to deciding upon the correct cloud details warehouse for your data platform, having said that, the response is not as uncomplicated. With the launch of Amazon Redshift in 2013 adopted by Snowflake, Google Huge Query, and other people in the subsequent decades, the marketplace has come to be more and more warm.
Increase information lakes to the blend, and the choice results in being that significantly more difficult.
No matter if you’re just having started out or are in the course of action of re-assessing your existing solution, here’s almost everything you require to know to pick the correct info warehouse (or lake) for your info stack:
What Would make a Info Warehouse or Lake?
Data warehouses and lakes are the basis of your data infrastructure, delivering the storage, compute ability and contextual information and facts about the info in your ecosystem. Like the motor of a motor vehicle, these systems are the workhorse of the info system.
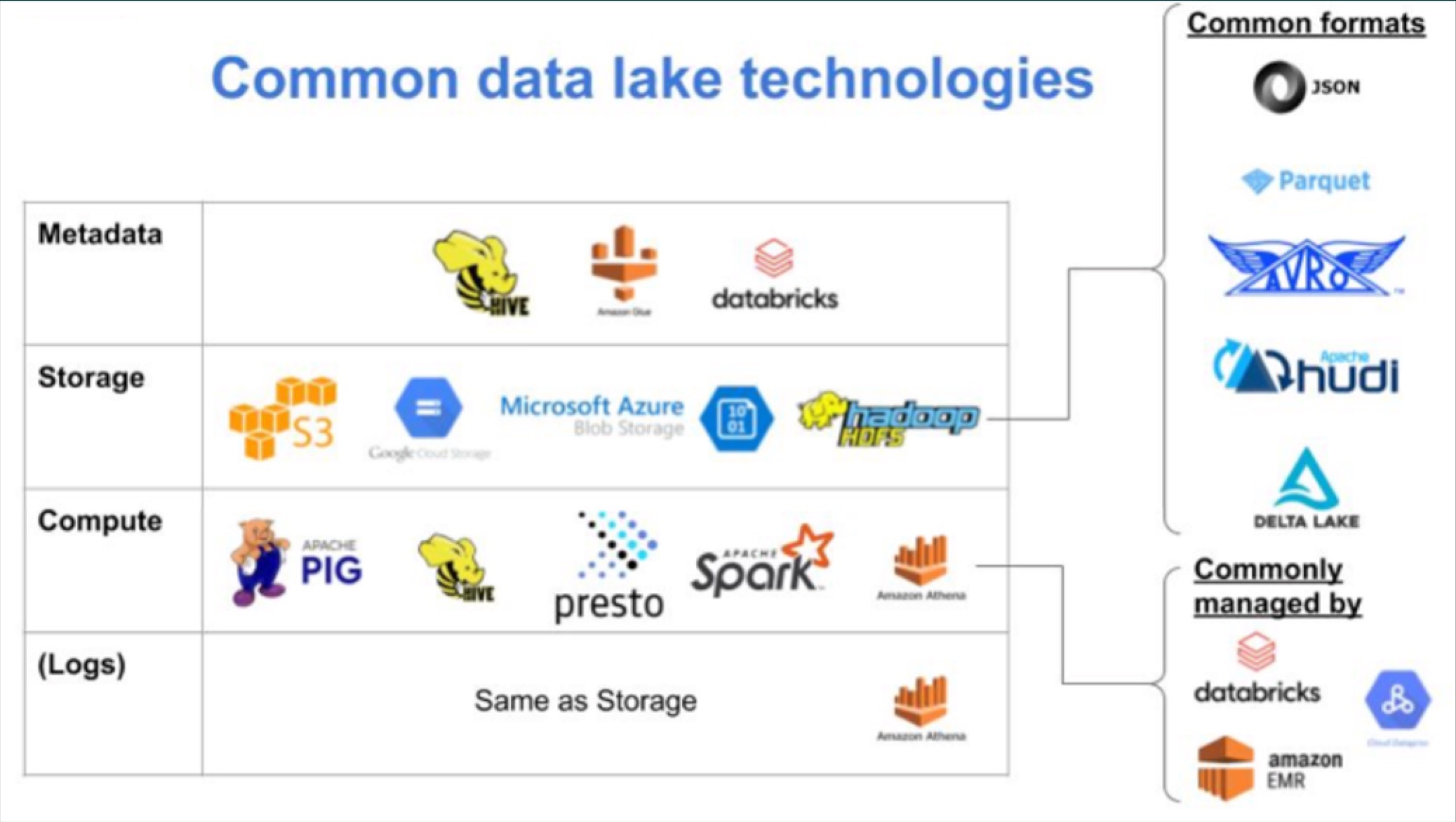
Knowledge warehouses and lakes include the following 4 most important factors:
Metadata
Warehouses and lakes usually offer a way to control and keep track of all the databases, schemas, and tables that you develop. These objects are typically accompanied by additional information and facts these types of as schema, facts styles, person-created descriptions, or even freshness and other stats about the information.
Storage
Storage refers to the way in which the warehouse/lake bodily retailers all the data that exist throughout all tables. By leveraging various forms of storage systems and knowledge formats, warehouses/lakes can serve a vast range of use situations with wanted expense/overall performance characteristics.
Compute
Compute refers to the way in which the warehouse/lake performs calculations on the knowledge records it stores. This is the motor that allows users to “query” knowledge, ingest information, transform it – and far more broadly, extract price from it. Routinely, these calculations are expressed by way of SQL.
Why Pick out a Facts Warehouse?
Facts warehouses are absolutely integrated and managed methods, generating them simple to create and work out of the box. When using a knowledge lake, you commonly use metadata, storage, and computing from a single resolution, crafted and operated by a one vendor.
As opposed to knowledge lakes, data warehouses usually call for extra framework and schema, which frequently forces superior info hygiene and effects in a lot less complexity when studying and consuming info.
Owing to its pre-packaged functionalities and potent help for SQL, info warehouses facilitate rapidly, actionable querying, building them terrific for info analytics teams.
Widespread facts warehouse technologies contain:
- Amazon Redshift: The very first widely well-liked (and conveniently obtainable) cloud knowledge warehouse, Amazon Redshift sits on best of Amazon Internet Solutions (AWS) and leverages supply connectors to pipe knowledge from uncooked data sources into relational storage. Redshift’s columnar storage composition and parallel processing make it ideal for analytic workloads.
- Google BigQuery: Like Redshift, Google BigQuery leverages its mothership’s proprietary cloud system (Google Cloud), uses a columnar storage format and requires edge of parallel processing for brief querying. Compared with Redshift, BigQuery is a serverless answer that scales in accordance to use patterns.
- Snowflake: Contrary to Redshift or GCP which rely on their proprietary clouds to function, Snowflake’s cloud info warehousing capabilities are powered by AWS, Google, Azure, and other public cloud infrastructure. Unlike Redshift, Snowflake lets consumers to pay separate costs for computing and storage, building the details warehouse a great solution for teams looking for a additional flexible pay framework.
Why Choose a Facts Lake?
Facts lakes are the do-it-your self edition of a facts warehouse, enabling info engineering teams to decide and decide on the various metadata, storage, and compute technologies they want to use based on the requirements of their units.
Knowledge lakes are great for information groups hunting to construct a far more custom-made platform, frequently supported by a handful (or more) of knowledge engineers.
- Decoupled storage and compute: Not only can this features make it possible for for significant expense personal savings, but it also facilitates parsing and enriching of the details for true-time streaming and querying.
- Guidance for distributed computing: Dispersed computing will help assist the functionality of huge-scale details processing simply because it permits for much better-segmented query efficiency, a lot more fault-tolerant design, and superior parallel information processing.
- Customization and interoperability: Owing to their “plug and chug” character, info lakes support knowledge platform scalability by producing it easy for various aspects of your stack to engage in properly alongside one another as the data demands of your business evolve and experienced.
- Largely designed on open up supply systems: This facilitates lessened vendor lock-in and affords fantastic customization, which operates well for organizations with massive details engineering teams.
- Capacity to cope with unstructured or weakly structured facts: Information lakes can help raw info, that means that you have bigger adaptability when it arrives to operating with your details, ideal for details researchers and data engineers. Doing the job with raw facts gives you much more handle above your aggregates and calculations.
- Supports refined non-SQL programming styles: Not like most information warehouses, data lakes guidance Apache Hadoop, Apache Spark, PySpark, and other frameworks for highly developed data science and machine understanding.
It’s significant to be aware that numerous facts warehouse solutions, including Snowflake and BigQuery, can help some of the over functionalities, which potential customers us to our following point…
Hold out, There is Extra: Introducing the Information Lakehouse
Just when you assumed the choice was tricky plenty of, a different details warehousing option has emerged as an increasingly preferred a single, specifically amid info engineering teams.
Meet the information lakehouse, a solution that marries characteristics of both of those data warehouses and knowledge lakes, and as a final result, brings together traditional knowledge analytics technologies with those designed for much more advanced computations (i.e., machine finding out).
Info lakehouses first arrived onto the scene when cloud warehouse companies started including attributes that provide lake-design added benefits, such as Redshift Spectrum or Delta Lake.
Likewise, data lakes have been incorporating technologies that offer you warehouse-style capabilities, these as SQL functionality and schema. Nowadays, the historic distinctions concerning warehouses and lakes are narrowing so you can obtain the greatest of both worlds in a single offer.
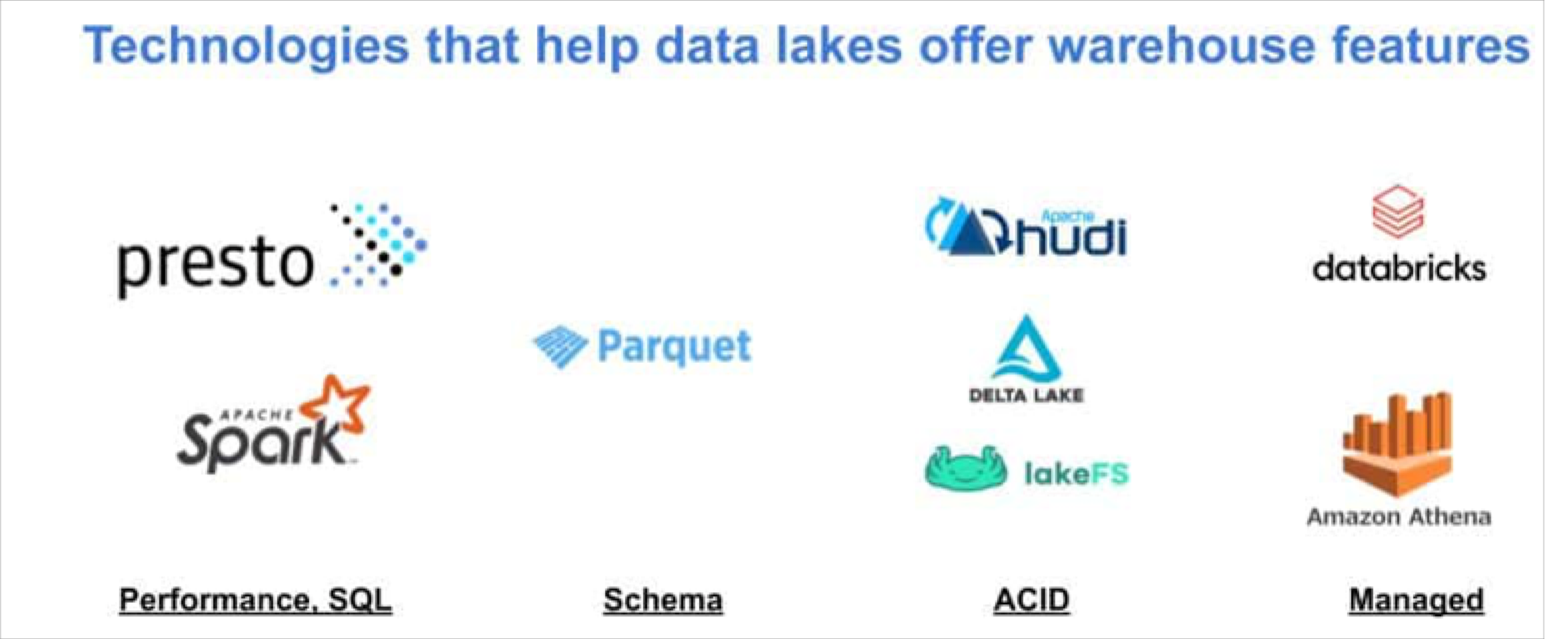
The following functionalities are helping details lakehouses even more blur the lines amongst the two technologies:
- Superior-functionality SQL: systems like Presto and Spark offer SQL interface at near to interactive speeds about details lakes. This opened the probability of facts lakes serving assessment and exploratory needs right, with out requiring summarization and ETL into conventional information warehouses.
- Schema: file formats like Parquet introduced a far more rigid schema to facts lake tables, as nicely as a columnar format for bigger question efficiency.
- Atomicity, Regularity, Isolation, and Durability (ACID): lake systems like Delta Lake and Apache Hudi introduced bigger dependability in produce/go through transactions, and normally takes lakes a step nearer to the remarkably appealing ACID houses that are standard in common database technologies.
- Managed expert services: for groups that want to lessen the operational carry affiliated with building and working a info lake, cloud providers provide a assortment of managed lake products and services. For example, Databricks gives a managed version of Apache Hive, Delta Lake, and Apache Spark when Amazon Athena features a thoroughly managed lake SQL question motor and Amazon’s Glue provides a thoroughly managed metadata provider.
With the increase of genuine-time details aggregation and streaming to advise lightspeed analytics (think Silicon Valley tech huge speeds: Uber, DoorDash, and Airbnb), knowledge lakehouses are probably to rise in attractiveness and relevance for knowledge teams throughout industries in the coming many years.
So, What Should really You Opt for?
There is not an uncomplicated reply. In truth, it’s no shock that facts teams frequently migrate from 1 facts warehouse remedy to yet another as the desires of their information corporation shift and evolve to meet up with the demands of data people (which today, is nearly each purposeful spot in the enterprise, from Internet marketing and Income to Operations and HR).
While details warehouses normally make perception for knowledge platforms whose primary use scenario is for info examination and reporting, knowledge lakes are starting to be ever more consumer-pleasant, specifically via managed data lakehouse options like Dremio and open supply assignments like Delta Lake.
Progressively, we’re acquiring that info groups are unwilling to settle for just a details warehouse, a knowledge lake, or even a knowledge lakehouse – and for great cause. As a lot more use instances arise and much more stakeholders (with differing skill sets!) are involved, it is practically extremely hard for a one option to serve all demands.
A single details leader we talked to at a 5,000-particular person ride-sharing organization told us that even however his details engineering team was adamant that they required to establish a information lake, they finished up putting in put an in-dwelling technique for reporting, accessibility handle, and information excellent that turned the last merchandise into more of a data warehouse.
We obtain that irrespective of the route you choose, it is significant to use the pursuing most effective practices:
Align on the Resolution(s) That Map to Your Company’s Details Targets.
If your business only works by using just one or two important data sources on a regular basis for a find couple workflows, then it might not make feeling to build a knowledge lake from scratch, equally in terms of time and methods.
But if your enterprise is striving to use facts to notify everything underneath the solar, then a hybrid warehouse-lake remedy could just be your ticket to fast, actionable insights for buyers throughout roles.
Know Who Your Core Consumers Will Be.
Will the major buyers of your information system be your company’s organization intelligence staff, distributed across numerous unique features? What about a devoted crew of facts engineers? Or a few teams of facts experts working A/B exams with numerous data sets? All of the over?
No matter, choose the details warehouse/lake/lakehouse option that makes the most perception for the ability sets and requires of your consumers.
Do not Neglect Knowledge Top quality.
Details warehouse, facts lake, info lakehouse: it doesn’t matter. All 3 remedies (and any mixture of them) will require a holistic tactic to knowledge governance and information top quality.
Your thoughtful financial commitment in the hottest and best information warehouse doesn’t issue if you cannot believe in your knowledge.
What is Up coming?
I’m enthusiastic to see exactly where the info sector is headed when it arrives to this foundational element of the data system. I forecast that a mature info stack will probable incorporate far more than 1 option, and details companies will eventually reward from higher charge savings, agility, and innovation.
[ad_2]