[ad_1]
RavenDB has been close to for a minimal around a decade and is at this time utilized by hundreds of consumers, which includes fortune 500 companies like Toyota and Verizon, but it hasn’t normally been clean sailing. Like any other software program, RavenDB has had its increasing pains, significantly in the early times when the corporation was designed up of just a handful of developers.
Person feedback has often performed an crucial purpose in our growth. Lots of of RavenDB’s characteristics were being added thanks to well-liked demand, and our shoppers have helped us find numerous obscure bugs by utilizing our program in ways we by no means could have imagined.
Even destructive comments has helped us increase. Thanks in part to our critics, quite a few of RavenDB’s weaknesses have turned into strengths.
“My mind-set is that if you thrust me towards some thing that you imagine is a weak point, then I will transform that perceived weakness into a strength.” – Michael Jordan
Some of RavenDB’s most infamous reviews assistance inform the tale.
Details Backup and Restore Operation
When Octopus switched to RavenDB, the responses (in 2012) was really optimistic. The only grievance they had was with OS compatibility in the backup system. The program was very bare-bones at the time and there was a large amount of room for advancement.
Backups are now performed immediately at user-described intervals and can be restored no matter of OS. There are also more disaster restoration possibilities to shield your details which we’ll get into later.
Even so, that short article was just a prelude to this brutal stick to-up in 2014.
Strengthening Database Usability, Documentation, and Studying Sources
The Octopus team identified that RavenDB was really opinionated and labored in mysterious methods. It was quick to make problems, there was very little in the way of advice or explanation, and documentation was unfortunately missing. To make matters worse, most organizations did not have RavenDB specialists on team to cope with troubles when they arose.
Lack of working experience/knowledge is a challenge for any new technological know-how, and NoSQL databases are nevertheless (relatively) new compared to their long-dominant relational counterparts. The alternative is to make the program intuitive, and simple to master and use.
At the time of these posts, we weren’t undertaking a good work of that and Paul’s criticisms weren’t unique. In response to our users’ opinions, we went all out to turn items close to.
We made the RavenDB studio: a GUI that allows you watch all factors of the databases and complete most capabilities just by pointing and clicking.
We included a wealth of documentation, and presently have various staff members doing the job full time incorporating and updating written content. Our CEO Oren Eini (also known as Ayende) wrote a whole (cost-free) ebook named Within RavenDB 4., which supplies a detailed rationalization of RavenDB and its fundamental style and design philosophy. We also developed a bootcamp software to assist new people get started off, so there’s no shortage of high-quality discovering product.
Updating the “Safe By Default” Strategy
Much of the Octopus team’s confusion and annoyance was prompted by RavenDB’s “safe by default” policy. It was a design philosophy aimed at stopping builders from “hurting themselves” with bad code.
Queries for each session were being limited and result sets had been bounded, and nevertheless the limits ended up acceptable, they weren’t made apparent. Exceeding the limits did not result in an error or notify the consumer: the ask for would just are unsuccessful quietly. This led to occasions where code would function in a different way in improvement than it would in output, with no crystal clear cause why.
There was negative comments from multiple sources regarding this and it led to a evaluation of our “safe by default” solution.
Consequence sets ended up originally minimal to 128, but are now unrestricted. It is now up to the user to code responsibly and use paging to hold final result sets modest and keep away from functionality decline.
Queries were minimal to 30 for every session because with additional than that you’re proficiently executing a DOS assault on yourself. Lazy requests make it possible for you to incorporate multiple calls into 1, so to get to 30 would get some quite abnormal (or just basic bad) code. You can now change this restrict (from the default 30) for those people abnormal situations.
MapReduce benefits were minimal to 15 for every merchandise mapped owing to the problem of reserving memory for fanout indexes. We have given that removed that restrict, but consumers will now obtain a performance notification if more than 1024 effects will be produced from a one doc.
In brief, thanks to consumer suggestions, RavenDB is a whole lot a lot less opinionated than it made use of to be, and capabilities a lot more in line with consumer expectations.
Just before finding to the rest of Paul’s criticisms, we require to demonstrate the largest basic modify RavenDB has long gone through due to the fact the time of his article.
RavenDB 4.: A Large Leap Ahead
Many challenges prospects experienced with RavenDB early on were being just much too elementary to take care of with smaller patches. We wanted a massive update to wholly overhaul RavenDB’s core techniques, and 4. was our possibility.
Our company went by a lot in preparation for 4.: the variety of developers on team doubled inside a yr and 8
And then, RavenDB took flight.

(You can see the whole Improvement Roadmap right here.)
Lastly, we could produce on the enhancements our customers experienced lengthy been waiting around for.
Now with that context, let’s get back again to Paul and Octopus. The previous item on the checklist higher than relates to Paul’s feedback about ESENT-linked indexing problems and bad functionality.
Databases Indexes and the Voron Storage Motor
We weren’t content with ESENT both, but we had been caught with it. It was flakey, sensitive, only worked on Windows, and sadly, the foundation for all of RavenDB’s storage and indexing.
4. is exactly where we made our split. We switched from .Net Framework to .Web Core to go over and above Home windows and we introduced our own custom-manufactured facts storage motor: Voron.
Voron is much much more secure and dependable than ESENT and is really optimized for our database product. Its introduction resulted in speeds expanding by orders of magnitude. With indexing rebuilt on this perfect foundation, it turned just one of the highlights of RavenDB.
Clarifying Eventual Regularity
On the topic of indexing in his short article “Would I use RavenDB all over again?,” Jeremy Miller talks about the issues of eventual regularity. Any time info is improved there’s a wait around before related (and now stale) indexes are up to date to be steady with the raw information. If you query an index that hasn’t been current you may well receive out-of-date details.
In RavenDB queries ought to be done from indexes. You cannot question uncooked details. This rule is for functionality sake, due to the fact querying an index is a lot quicker, but what about stale indexes?
We do not in fact allow indexes keep stale extensive (they are updated immediately after 5ms) and in most instances, they current no complications. Having said that, in conditions in which regularity is critical, RavenDB has the answers – you can check out for stale reads or make queries wait for indexes to be current.
Whilst we haven’t adjusted our tactic to eventual regularity, we have manufactured it a lot clearer with our introductory and mastering components.
MapReduce Customization
In his post “Migrating from RavenDB to Cassandra,” Aaron Stannard usually takes situation with the way RavenDB implements MapReduce, with these two complaints:
-
RavenDB’s MapReduce technique required re-aggregation “which works good at reduced volumes but scales at an inverted ratio to data progress.”
This is a minor bewildering. RavenDB performs incremental aggregation and has under no circumstances expected re-aggregation. As a end result, efficiency is superb irrespective of information development.
-
The MapReduce pipeline was also simplistic, which prevented them from accomplishing a lot more in-depth personalized queries.
This criticism experienced benefit, and we responded by opening the door for user customization. Now you can simply add your have code to RavenDB’s map/reduce pipeline and make it do whatever you want.
We’re in fact actually proud of our MapReduce technique as a entire, so we developed an full webinar devoted to it.
What’s Occurring With Sharding?
Aaron also had some quite legitimate criticism of RavenDB’s sharding system:
“Raven’s sharding system is truly far more of a hack at the consumer stage which marries your network topology to your info, which is a actually terrible layout choice…”
Aaron was suitable on the income – it wasn’t excellent. We made the decision to abandon our customer-side simulation of sharding and are now doing work to introduce true sharding in our up coming important update: Edition 6..
Introducing In-Memory Tests
Yet another problem elevated by Jeremy Miller was RavenDB’s lack of in-memory screening. At the time this was a hole in our element set, just one we loaded with a a lot more than enough remedy.
Like other systems, RavenDB now provides a fully in-memory method for database screening. It is blazingly fast, you can set it up with 1 line of code, and you can use it for automatic tests in a CI/CD pipeline.
Compared with other programs*, the in-memory model will behave identically to how your database does in generation, making certain your results are always legitimate.
*In Microsoft’s documentation for entity framework:

Database Superior-Availability and Catastrophe Recovery
In his article, “Initial ideas on Octopus Deploy 3. – from RavenDB back again to SQL Server,“ Ian Paullin talks about his organization’s absence of HA/DR options with RavenDB.
These have been serious troubles and we dealt with them accordingly.
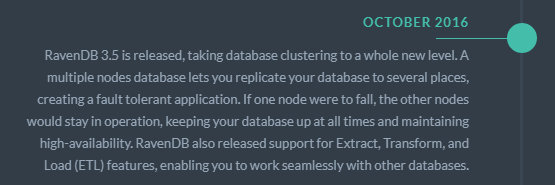
As the notes say, clustering delivers terrific fault tolerance. Something they do not point out is that RavenDB makes clusters very simple to set up and take care of.
RavenDB is finest operate on clusters of at the very least 3 nodes, that way if 1 or two nodes are unsuccessful your databases will however remain up and working. Automated replication and assignment failover secure your data, when functions like load balancing and concurrent reads and writes give considerable performance added benefits.
RavenDB also works by using hashing to retain an eye out for information corruption. You can substitute the impacted tricky disk and replicate your databases again to that node.
If you do not have the information replicated to yet another node or backed up, the Voron restoration tool can still help you get it back.
Extra Programming Language Assist
In his post “Thoughts on MongoDB vs Standard SQL and RavenDB,” John Culviner pointed out that RavenDB “suffered from bugs and a sub-par CLI/querying API (except you were applying C#).”
This was a legitimate criticism at the time. Early in development, we focused generally on C#, and aid for other languages lagged powering.
We’ve always gained a lot of feedback on this problem, and we’re always striving to accommodate. At the time of creating we have clientele for C#, Java, Node.js, Python, Ruby, and Go.
The Submit-4. Era
Negative article content and testimonials are a great deal tougher to find after the release of 4.. The most important critique arrives from lengthy-term user Alex Klause in his article titled “RavenDB: Two A long time of Discomfort and Pleasure.” Alex experienced a ton of fantastic to say, but there ended up some disappointing negatives as properly.
His very first criticism was about a absence of documentation and community. It is accurate that RavenDB doesn’t have the most important group, even though it has developed significantly considering that the time of the posting. We offset this by supplying intensive support on our group community forums, as a result of aid offers accessible to our shoppers, and by delivering comprehensive documentation and learning elements.
The up coming concern was the inexcusable amount of (immediately mounted) bugs.
Sadly for Alex, he started off utilizing RavenDB soon ahead of our biggest established of modifications at any time. In the interval he utilized RavenDB (v3.5 – v4.2), a set of outdated bugs had been waiting to be squashed, only to be replaced in 4. by a full new established just ready to be uncovered. It was a wild time, and matters have settled down a whole lot given that then. These days, bugs are far significantly less common and considerably less sizeable.
Profiling RavenDB
As Alex noted, and as is however the circumstance, RavenDB doesn’t have a single committed profiler. As an alternative, it now has a number of profiling resources, all of which you can obtain and use within the studio.
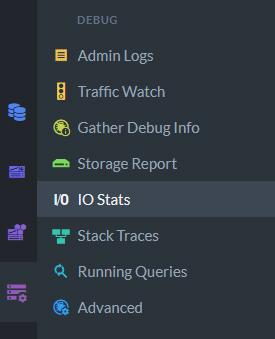 With these equipment, you can observe and debug practically just about every component of your database’s operations in our intuitive and aesthetically pleasing GUI.
With these equipment, you can observe and debug practically just about every component of your database’s operations in our intuitive and aesthetically pleasing GUI.
Raven Question Language (RQL)
Oren also dealt with the reviews about RQL, but the confusion is understandable. A fantastic comprehending of RQL involves a superior clarification, and as described our finding out resources ended up lacking at the time. A good rationalization can now be located in Oren’s e-book.
[ad_2]