[ad_1]
On July 26, 2004, a 5-calendar year-previous startup by the name of Google was confronted with a critical trouble: their software was down.
For quite a few hrs, end users throughout the United States, France, and Excellent Britain have been unable to obtain the common look for engine. The then-800-human being enterprise and its tens of millions of end users were being left in the dark as engineers struggled to deal with the trouble and uncover the root trigger of the difficulty. By midday, a tiresome and intense system performed by a number of panicked engineers established that the MyDoom virus was to blame.
In 2021, an outage of that length and scale is deemed rather anomalous, but 15 years in the past, these types of software outages weren’t out of the normal. Following main groups by means of numerous of these activities around the yrs, Benjamin Treynor Sloss, a Google engineering manager at the time, identified there had to be a greater way to regulate and prevent these dizzying hearth drills, not just at Google but across the field.
Encouraged by his early job setting up information and IT infrastructure, Sloss codified his learnings as an solely new self-discipline — web page reliability engineering (SRE) — dedicated to optimizing the upkeep and functions of program methods (like Google’s look for motor) with reliability in mind.
According to Sloss and some others paving the way forward for the self-discipline, SRE was about automating absent the have to have to get worried about edge cases and unfamiliar unknowns (like buggy code, server failures, and viruses). In the long run, Sloss and his staff preferred a way for engineers to automate absent the handbook toil of sustaining the company’s speedily increasing codebase when ensuring that their bases were protected when techniques broke.
“SRE is a way of pondering and approaching manufacturing. Most engineers creating a procedure can also be an SRE for that procedure,” he claimed. “The problem is: can they get a intricate, perhaps not a well-described issue and arrive up with a scalable, technically acceptable alternative?”
If Google experienced the appropriate processes and systems in area to foresee and avert downstream concerns, not only could outages be quickly fastened with small effect on consumers, but prevented altogether.
Knowledge Is Software program and Application Is Knowledge
Just about 20 yrs afterwards, facts teams are faced with a similar destiny. Like software program, facts techniques are getting progressively intricate, with various upstream and downstream dependencies. 10 or even five many years back, it was regular and accepted to take care of your information in silos, but now, teams and even entire organizations are performing with knowledge, facilitating a far more collaborative and fault-resistant technique to info administration.
About the past handful of a long time, we have witnessed the common adoption of computer software engineering most effective tactics by info engineering and analytics groups to handle this gap, from adopting open source tools like dbt and Apache Airflow for less complicated info transformation and orchestration to cloud-centered data lakes and details warehouses.
Basically, this shift to agile rules relates to how we conceptualize, design and style, build, and retain details systems. Extensive absent are the times of siloed dashboards and reports that are produced at the time, seldom employed, and hardly ever up to date now, to be practical at scale, knowledge must also be productized, taken care of, and managed for intake by stop-customers throughout the organization.
And in order for facts to be taken care of like a computer software product, it has to be as responsible as a single, much too.
The Rise of Knowledge Reliability
In small, details trustworthiness is an organization’s means to produce substantial knowledge availability and health and fitness throughout the total details lifecycle, from ingestion to the finish solutions: dashboards, ML styles, and production datasets. In the earlier, consideration has been offered to addressing diverse pieces of the puzzle in isolation, from tests frameworks to data observability, but this approach is no for a longer time ample. As any facts engineer will tell you, on the other hand, data reliability (and the skill to really deal with information like a merchandise) is not realized in a silo.
A schema transform in one particular data asset can affect a number of tables and even fields downstream in your Tableau dashboards. A missing worth can mail your finance crew into hysterics when they’re querying new insights in Looker. And when 500 rows quickly turn into 5,000, it is usually a indication that something is not right – you just never know wherever or how the table broke.
Even with the abundance of fantastic information engineering resources and sources that exist, information can crack for tens of millions of diverse reasons, from operational concerns and code changes to difficulties with the info by itself.

From my own practical experience and after speaking to hundreds of groups, there are presently two means most knowledge engineers explore data good quality issues: testing (the best result) and indignant messages from your downstream stakeholders (the likely result).
In the identical way that SREs regulate application downtime, today’s data engineers will have to concentrate on reducing details downtime — periods of time when info is inaccurate, lacking, or usually faulty — by automation, steady integration, and steady deployment of info styles, and other agile rules.
In the earlier, we’ve reviewed how to develop a swift and dirty information platform now, we’re building on this design and style to replicate the next step in this journey toward superior knowledge: the data dependability stack.
Here’s how and why to construct one particular.
Introducing: the Facts Dependability Stack
Presently, information groups are tasked with making scalable, highly performant information platforms that can tackle the needs of cross-useful analytics groups by storing, processing, and piping facts to make correct and well timed insights. But to get there, we also have to have the correct approach to making certain that raw information is usable and honest in the to start with area. To that close, some of the greatest teams are constructing data trustworthiness stacks as element of their modern facts platforms.
In my view, the modern day info trustworthiness stack is produced up of 4 distinctive levels: tests, CI/CD, data observability, and information discovery, each and every representative of a diverse stage in your company’s data high quality journey.
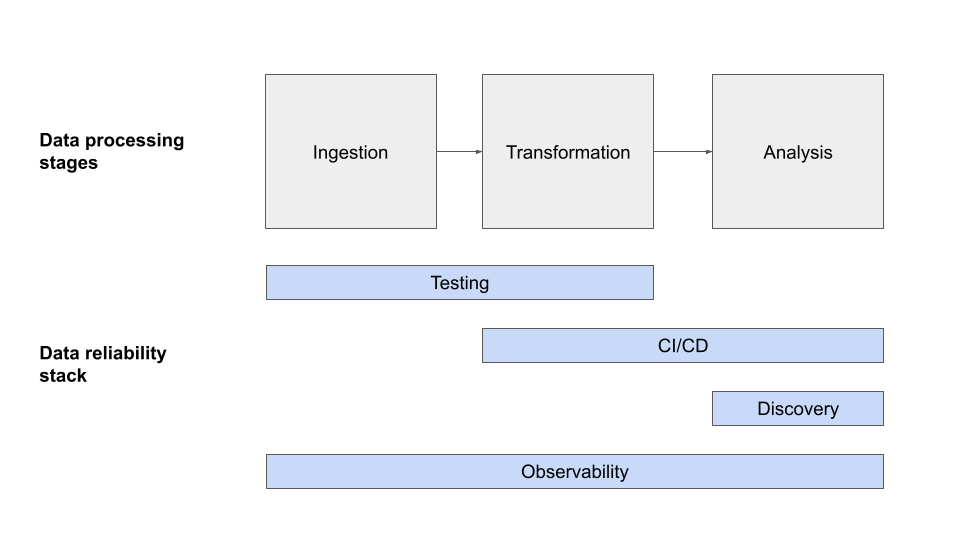
Information Testing
Screening your details plays a vital function in identifying data quality difficulties just before it even enters a generation details pipeline. With tests, engineers foresee a little something could possibly break and produce logic to detect the situation preemptively.
Details tests is the system of validating your organizations’ assumptions about the information, either ahead of or for the duration of output. Composing standard exams that examine for items this kind of as uniqueness and not_null are approaches corporations can examination out the primary assumptions they make about their supply info. It is also popular for companies to be certain that facts is in the proper structure for their team to function with and that the facts meets their enterprise requires.
Some of the most common facts high-quality checks consist of:
- Null values – are any values mysterious (NULL)?
- Volume – Did I get any data at all? Did I get as well much or far too minor?
- Distribution – is my info inside an recognized selection? Are my values in-range within a specified column?
- Uniqueness – are any values duplicated?
- Recognized invariants – is revenue constantly the distinction among profits and cost, or some other properly recognized details about my information?
From my own practical experience, two of the greatest tools out there to examination your knowledge are dbt assessments and Excellent Anticipations (as a additional normal-function instrument). The two tools are open resource and permit you to discover details excellent challenges before they end up in the fingers of stakeholders. Even though dbt is not a testing resolution for every se, their out-of-the-box exams operate well if you are by now utilizing the framework to model and renovate your knowledge
Continuous Integration (CI) / Continual Delivery (CD)
CI/CD is a critical element of the computer software growth lifetime cycle that makes sure new code deployments are stable and reputable as updates are built about time, by means of automation.
In the context of information engineering, CI/CD relates not only to the process of integrating new code consistently but also to the course of action of integrating new information into the technique. By detecting difficulties at an early stage, ideally as early as code is committed, or new data is merged – knowledge teams are ready to arrive at a speedier, extra reputable growth workflow.
Let us start out with the code part of the equation. Just like common software engineers, data engineers profit from using supply manage, for example, Github, to take care of their code and transformations so that new code can be adequately reviewed and model managed. A CI/CD program, for case in point, CircleCI or Jenkins (open resource), with a fully automated tests and deployment setup can create a lot more predictability and consistency in deploying code. This need to all sound very acquainted.
Where by data groups encounter an additional level of complexity is the obstacle of understanding how code improvements may well effect the dataset that it outputs. That’s where by rising instruments like Datafold arrive in – enabling teams to compare the info output of a new piece of code to a past operate of that similar code. By catching sudden details discrepancies early in the approach, prior to code is deployed, increased dependability is achieved. While consultant staging or generation knowledge is expected for this process, it can be very successful.
There is also one more household of instruments intended to support teams ship new knowledge, fairly than new code, much more reliably. With LakeFS or Undertaking Nessie, groups are in a position to phase their knowledge before publishing it for downstream usage with git-like semantics. Picture producing a department with newly processed data, and only committing it to the major branch if it’s deemed great! In conjunction with testing, info branching can be a really highly effective way to block negative details from ever reaching downstream consumers.
Info Observability
Tests and versioning facts pre-output is a terrific 1st stage towards accomplishing details trustworthiness, but what occurs when knowledge breaks in production–and over and above?
In addition to aspects of the knowledge reliability stack that deal with info quality ahead of transformation and modeling, info engineering teams require to make investments in close-to-conclude, automated information observability methods that can detect when info problems occur in near-genuine-time. Very similar to DevOps Observability answers (i.e., Datadog and New Relic), info observability uses automated monitoring, alerting, and triaging to determine and evaluate details top quality concerns.

- Freshness: Is the information current? When was the final time it was created? What upstream information is involved and or omitted?
- Distribution: Is the details within just approved ranges? Is it the proper format? Is it complete?
- Volume: Has all the facts arrived? Was information duplicated by incident? How a great deal facts was taken out from a table?
- Schema: What is the schema, and how has it altered? Who built variations to the schema and for what causes?
- Lineage: For a provided knowledge asset, what are the upstream and downstream resources that are impacted by it? Who are the one’s building this data, and who is relying on the information for selection creating?
Details observability accounts for the other 80
With these resources, your team will be effectively-geared up to not just tackle but also reduce very similar concerns from happening in the foreseeable future as a result of historical and statistical insights into the reliability of your details.
Knowledge Discovery
Even though not customarily considered a element of the trustworthiness stack, we believe that details discovery is critical. A single of the most common strategies groups build unreliable knowledge is by overlooking belongings that already exist and building new datasets that appreciably overlap, or even contradict, existing types. This makes confusion among customers in the organization about which details is most relevant for a certain enterprise dilemma, and diminishes trust and perceived dependability.
It also makes a large amount of facts debt for facts engineering teams. With no good discovery in place, teams obtain themselves needing to keep dozens of distinctive datasets all describing the exact dimensions or information. The complexity by yourself makes further more growth a obstacle, and high dependability incredibly hard.
Even though facts discovery is an exceptionally tough challenge to fix, details catalogs have produced inroads to bigger democratization and accessibility. For occasion, we have witnessed how solutions like Atlan, facts.globe, and Stemma can deal with these two concerns.
Concurrently, knowledge observability options can enable do away with a good deal of the typical perceived dependability issues and details financial debt difficulties necessary to obtain facts discovery. By pulling jointly metadata, lineage, high-quality indicators, usage patterns as well as human produced documentation, details observability can response inquiries like: what facts is readily available to me to describe our customers? Which dataset should really I belief most? How can I use that dataset? Who are the professionals that can support remedy inquiries about it? In short, these tools introduce a way for information consumers and producers to discover the dataset or report they need and keep away from these duplicated attempts.
Democratizing this facts and earning it offered to any particular person that uses or produces details is a crucial piece of the dependability puzzle.
The Long term of Knowledge Trustworthiness
As the details becomes extra and additional integral to the day-to-day functions of modern day business enterprise and powers digital solutions, the require for responsible information will only maximize, as will the complex needs all-around making certain this have confidence in.
However, although your stack will get you some of the way there, details dependability is not solved with technology by yourself. The strongest methods also integrate society and organizational shifts to prioritize governance, privacy, and stability, all a few parts of the modern-day facts stack ripe for acceleration for the up coming various a long time.
A different effective resource in your information trustworthiness arsenal is to prioritize assistance-amount agreements (SLAs) and other steps to track the frequency of difficulties relative to agreed expectations set with your stakeholders, another tried out and genuine finest practice gleaned from computer software engineering. This kind of metrics will be crucial as your organization can make the move towards treating info like a product and info groups a lot less like economical analysts much more like item and engineering teams.
In the meantime, here’s wishing you no information downtime – and a great deal of uptime!
[ad_2]