[ad_1]
What do you do when you have million-greenback devices in your producing pipeline giving you sleepless evenings? To mitigate possibility, you may possibly generate a digital counterpart of your physical asset, commonly recognised as the Digital twin , and leverage augmented intelligence derived from knowledge streams. IoT tends to make the answer affordab,le and major data allows analytics at scale. For streaming analytics, there is a bounded timeline during which motion demands to be taken to regulate method or asset parameters. Digital twin and stream analytics can aid make improvements to the availability of assets, enhance quality in the producing course of action and assistance in obtaining RCAs for failures.
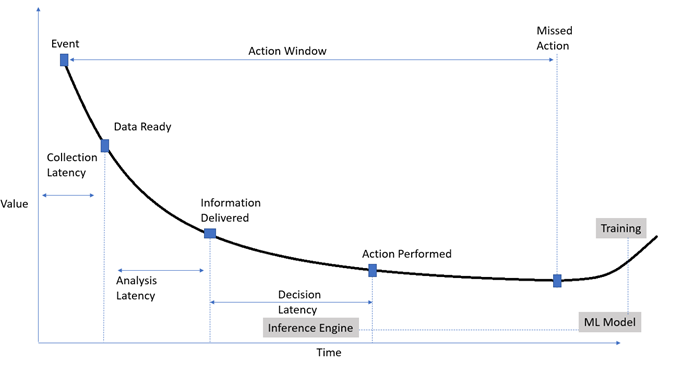
For related analytics use cases, I see Spark streaming most effective suited as portion of the option because of to its open up-source and effortless-to-software APIs.
We will go over the flawless style with respect to scalability, latency, and fault tolerance by leveraging the most current features of Spark, and Kafka.
Spark Framework
Spark at this time features two frameworks for spark stream processing –
- Spark streaming framework- This framework is dependent on Resilient Dispersed Datasets [RDD], which process gatherings in micro-batches.
kafkaDStream = KafkaUtils.createDirectStream(spark_streaming,[topic],"metadata.broker.record": brokers)
def handler(concept):
data = concept.obtain()
for record in information:
print(json.masses(file[1]))
payload = json.loads(record[1])
print(payload["temp_number"])
kafkaDStream.foreachRDD(lambda rdd: handler(rdd))2. Structural Streaming-based Spark framework – This framework is centered on a knowledge body that is optimized for general performance, and provides aid for both equally micro-batches with latency(~100ms at ideal) and ongoing stream processing with millisecond latency(~1ms). Ongoing processing is a new, experimental streaming execution method
df = (
spark
.readStream
.structure("kafka")
.possibility("kafka.bootstrap.servers", "area.azure.confluent.cloud:9092")
.solution("kafka.safety.protocol", "SASL_SSL")
.solution("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.widespread.safety.simple.PlainLoginModule needed username="" password=''".format(CLUSTER_API_Vital, CLUSTER_API_Top secret))
.option("kafka.ssl.endpoint.identification.algorithm", "https")
.choice("kafka.sasl.system", "Basic")
.option("subscribe", kafka_subject matter_name)
.selection("startingOffsets", "earliest")
.possibility("failOnDataLoss", "untrue")
.load()
.withColumn('fixedValue', fn.expr("substring(benefit, 6, duration(benefit)-5)"))
.find('topic', 'partition', 'offset', 'timestamp', 'fixedValue')
)
show(df)
Kafka Streaming System
To supply info buffering layer involving data producer IoT products, and backend spark individuals, the streaming system plays a important position with information responsible processing assures, message replay, and retention ability. The streaming system permits a question system for Spark customers to poll occasions at standard intervals. These situations are then included to the unbounded enter desk in the Spark structural streaming framework.
Fault Tolerance
In advance of structural streaming, it was the developer’s nightmare to prevent duplicate writes for incoming messages. Structural Streaming will make the enhancement model straightforward as “precisely-the moment” is enabled by applying transactional knowledge sources and checkpointing sinks for micro-batch bring about intervals.
Kafka Celebration streaming platform serves as the data source for Spark streaming with offset-centered commits. This offset functionality enables Spark Structural Streaming apps the means to restart and replay messages from any point in time. Structured Streaming can make sure just-after message processing semantics beneath any failure using replayable sources and idempotent sinks like a key-benefit shop.
The streaming query can be configured with a checkpoint place, and the query will save all the offset development information and facts and the managing aggregates to the checkpoint area.
These checkpointing and generate-in advance logs support recover the past good point out in circumstance of failure for re-generating RDDs.
How to Scale Stream Processing?
By default, the number of executors needed on the Spark cluster will be equal to the number of partitions. Escalating Kafka partition to Spark executor partition ratio will improve Spark Structural Stream throughput for intake of messages although adding to processing price.
If the facts in the Kafka partition is needed to be further more break up for Spark processing, the Spark partition limit can be elevated by the “minPartitions” configuration. For 10 partitions of Kafka stream, 20 partitions can be specified as “minPartitions” in Spark work configuration.
Function Timestamp Processing
Spark Structural Streaming procedures situations primarily based on incoming event timestamp, therefore enabling dealing with of late-arriving details and watermarking threshold for this sort of events. Former Spark streaming framework can method events only based mostly on technique or processing timestamp. Therefore Structural Streaming makes feasible aggregations on Home windows in excess of Function-Time, say, very last 5 minutes. Tumbling window[window duration is the same as sliding duration] and overlapping window[window duration is greater than sliding duration] aggregation are attainable applying celebration time. This element is handy in situation there is community latency for incoming IoT knowledge.
Hybrid joins in between streaming knowledge, and static dataset has less difficult facts body-dependent API with structural streaming. Join API can be leveraged to enrich incoming streaming knowledge with static master knowledge to be certain completeness of report info or for validation.
Platform and Provider Choices
Below are support choices from top cloud-dependent platforms. Dependent on the use scenario and assistance suitability, a service can be selected for the streaming answer.
|
Platform |
|||||
|
Azure |
AWS |
Cloudera |
GCP | ||
| Providers | Spark | Databricks, HDInsight | EMR, Glue | Data Engineering | Dataproc |
| Kafka | Occasion Hub, HDInsight, Confluent | MSK, Confluent | CDP Streams Messaging | Confluent | |
Spark Structural Streaming and Kafka streaming system with each other can be leveraged to deliver a true event-primarily based, fault-tolerant, and remarkably scalable stream processing framework for genuine-time Electronic twin streaming analytics use scenarios.
[ad_2]