[ad_1]
Kubernetes checking is the method of accumulating metrics from the Kubernetes clusters you function to identify vital gatherings and assure that all hardware, application, and programs are running as predicted. Monitoring is vital to provide insight into cluster health, useful resource intake, and workload efficiency. With the correct monitoring, problems that come about in any layer of the stack can be immediately identified and corrected.
There are several Kubernetes checking tools, including open up-resource applications like Prometheus and the ELK Stack as properly as industrial resources which includes Datadog, Cloudwatch, and New Relic.
Of the open up-source Kubernetes checking resources, Prometheus is between the most popular and commonly utilised. This write-up discusses the use of Prometheus to check Kubernetes and Kubernetes apps.
What Is Prometheus?
Prometheus is an open up-resource celebration monitoring and alerting tool that was originally produced at SoundCloud starting in 2012, encouraged by the Borgmon instrument used at Google. Prometheus has been a Cloud Native Computing Basis (CNCF) challenge because 2016 it was the second hosted undertaking after Kubernetes. Though this posting discusses Prometheus in the context of Kubernetes monitoring, it can fulfill a wide assortment of monitoring requires.
Prometheus collects and merchants the metrics you specify as time sequence information. Metrics can be analyzed to understand the operational point out of your cluster and its elements.
An vital focus of Prometheus is reliability. This can help ensure that Prometheus stays accessible if other matters are misbehaving in your natural environment. Just about every Prometheus server is stand-by yourself. A neighborhood time collection databases will make it unbiased from remote storage or other remote companies. This can make it beneficial for fast figuring out concerns and getting actual-time responses on technique effectiveness for the clusters and applications currently being monitored.
The major parts of Prometheus, including the Prometheus server and the Alertmanager, are shown in the determine beneath. Prometheus also offers a Pushgateway, which makes it possible for quick-lived and batch careers to be monitored. The Prometheus shopper library supports instrumenting software code. A powerful question language (PromQL) will make it doable to simply query Prometheus and drill down to fully grasp what is going on. Even though Prometheus features a net UI, it is normally applied in blend with Grafana for additional flexible visualization.
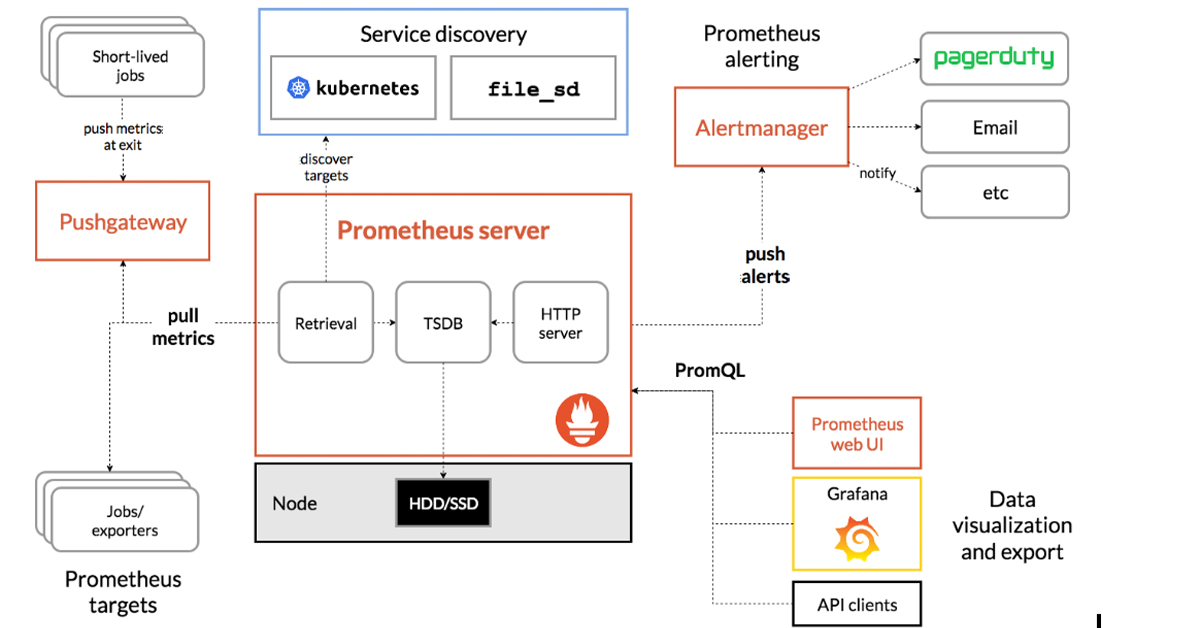
Source: Prometheus.io
A single of the issues that contributes to the level of popularity of Prometheus is that a lot of integrations exist, like integrations with several languages, databases, and other checking and logging resources. This presents you the adaptability to go on to use the equipment and techniques you currently have.
Preparing a Prometheus Deployment
A successful Prometheus deployment needs some up-entrance planning. Very first, it is essential to keep track of who is accessing your clusters and what they are accomplishing so variations can be monitored and rolled again if important. You also want to cautiously consider what cluster and application metrics you need to collect to assistance you discover and remediate concerns, and what additional visualization resources (if any) you will use to make perception of the facts you accumulate.
Prometheus uses storage successfully but gathering metrics that really do not insert price will consume storage and price you money. As your deployments become multi-cluster and multi-cloud, it will become critical to harmony the price of metrics retained versus storage charges. As pointed out previously mentioned, Prometheus likes to store metrics regionally. Think about and spending budget for distant storage for extended-term retention if necessary.
If you’re heading to use Prometheus to check in-residence Kubernetes purposes, you will likely will need to produce just one or extra brokers to deliver the right instrumentation. Make guaranteed the output from the agent can make feeling to the individuals who will receive the alerts.
Prometheus Problems With Massive Kubernetes Fleets
The standalone design of Prometheus introduces a particular quantity of complexity, primarily as your Kubernetes fleet grows to incorporate lots of clusters — perhaps operating unique Kubernetes distributions in various cloud environments. A significant operation with several clusters can very easily exceed the capabilities of a solitary Prometheus server and its associated storage. That means you must possibly reduce the selection of metrics you are amassing or scale the range of Prometheus servers.
There are numerous means to scale your Prometheus backend. Prometheus servers have the capability to scrape info from other Prometheus servers, so you can federate servers. Prometheus supports possibly a hierarchical or federated product. These approaches require very careful organizing and increase complexity, especially as your operations carry on to scale.
Prometheus also presents a way to integrate with remote storage destinations through an API that lets creating and studying metrics utilizing a distant URL. This enables you to get all your info in a single spot, but you are going to want added tooling to consider advantage of that aggregated data. A lot of companies include Thanos or Cortex to their toolsets to combination knowledge and provide lengthy-phrase storage and a worldwide see.
Although these hurdles are not insurmountable, it’s critical to assume about the supplemental arranging and ongoing management that will be required. Mainly because of the complexity of checking large Kubernetes environments, lots of corporations prefer monitoring as a company.
[ad_2]