[ad_1]
Deep discovering is witnessing a escalating history of achievements. On the other hand, the significant/large styles that must be run on a high-efficiency computing system are significantly from exceptional. Synthetic intelligence is currently commonly made use of in small business apps. The computational needs of AI inference and training are increasing. As a end result, a fairly new course of deep understanding approaches recognized as quantized neural community designs has emerged to tackle this disparity. Memory has been one of the greatest difficulties for deep studying architectures. It was an evolution of the gaming marketplace that led to the speedy advancement of components main to GPUs, enabling 50 layer networks of today. Nevertheless, the starvation for memory by newer and highly effective networks is now pushing for evolutions of Deep Studying design compression techniques to set a leash on this need, as AI is swiftly transferring towards edge products to give near to authentic-time success for captured information. Design quantization is a single this sort of rapidly escalating technologies that has permitted deep learning models to be deployed on edge units with fewer power, memory, and computational ability than a total-fledged laptop.
How Did AI Migrate From Cloud to Edge?
Several corporations use clouds as their main AI engine. It can host demanded info by way of a cloud info heart for executing intelligent conclusions. This system of uploading data to cloud storage and conversation with details centers induces a delay in creating true-time conclusions. The cloud will not be a viable option in the upcoming as demand for IoT programs and their authentic-time responses grows. As a final result, AI on the edge is becoming far more well-known.
Edge AI typically operates in a decentralized fashion. Little clusters of computer products now do the job together to travel conclusion-creating instead than going to a big processing heart. Edge computing boosts the device’s true-time reaction considerably. Yet another benefit of edge AI more than cloud AI is the reduce price tag of procedure, bandwidth, and connectivity. Now, this is not simple as it appears. Operating AI models on the edge equipment even though protecting the inference time and substantial throughput is equally challenging. Design Quantization is the essential to solving this problem.
The Require for Quantization?
Now right before heading into quantization, let’s see why a neural community in standard takes so much memory.
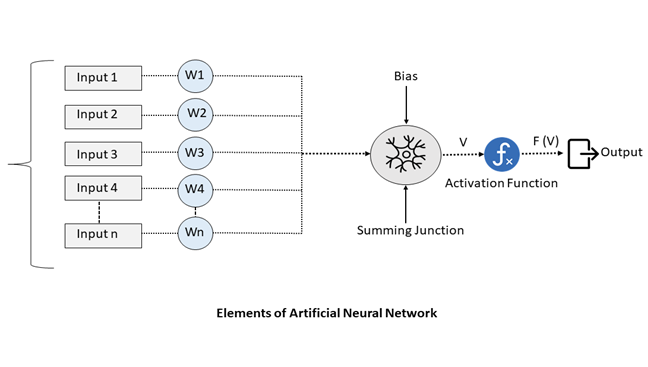
As revealed in the over figure, a standard synthetic neural network will consist of layers of interconnected neurons, with each individual obtaining its very own bodyweight, bias, and activation perform. These weights and biases are referred to as the “parameters” of a neural network. This receives stored bodily in memory by a neural network. Conventional 32-bit floating-level values are a common representation for them, letting a significant degree of precision and accuracy for the neural network.
Finding this accuracy makes any neural network choose up a good deal of memory. Visualize a neural community with millions of parameters and activations, acquiring saved as a 32-bit value, and the memory it will consume. For instance, a 50-layer ResNet architecture will consist of approximately 26 million weights and 16 million activations. So, working with 32-bit floating-point values for the two the weights and activations would make the overall architecture consume close to 168 MB of storage. Quantization is the large terminology that includes distinctive approaches to convert the enter values from a massive set to output values in a smaller established. The deep mastering styles that we use for inferencing are almost nothing but matrices with sophisticated and iterative mathematical operations, which generally include things like multiplications. Converting individuals 32-little bit floating values to the 8-bit integer will reduce the precision of the weights employed.
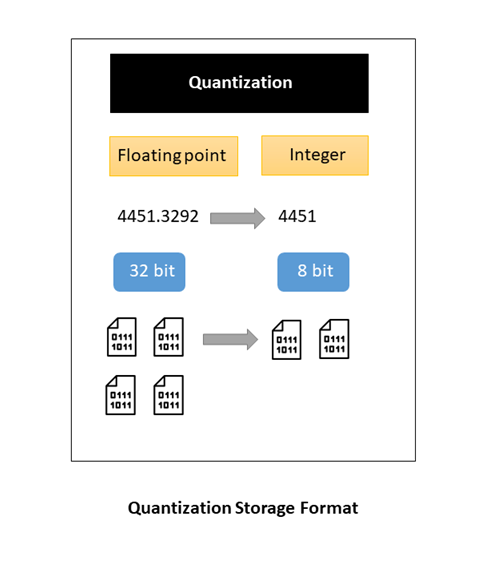
Thanks to this storage format, the footprint of the model in the memory receives reduced, and it greatly enhances the efficiency of types. In deep mastering, weights, and biases are stored as 32-bit floating-level quantities. When the product is experienced, it can be lessened to 8-bit integers, which ultimately minimizes the design dimensions. Just one can both lessen it to 16-bit floating factors (2x dimensions reduction) or 8-little bit integers (4x measurement reduction). This will appear with a trade-off in the accuracy of the model’s predictions. Even so, it has been empirically verified in a lot of scenarios that a quantized model does not suffer from a major decay or no decay at all in some eventualities.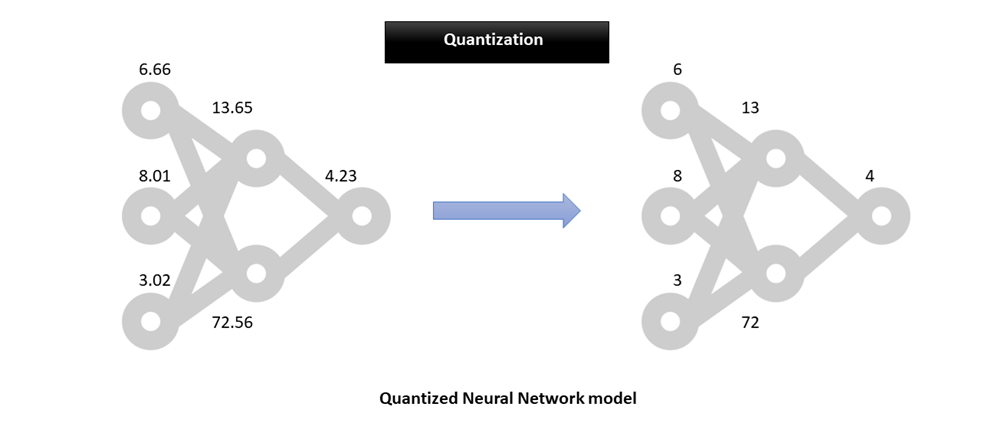
How Does the Quantization Process Work?
There are two methods to do model quantization, as described under.
Article Teaching Quantization
As the name implies, post-coaching quantization is a method of changing a pre-properly trained design to a quantized product, viz. converting the product parameters from 32-bit to 16-bit or 8-bit. It can further more be of two sorts. One is hybrid quantization, where by you just quantize weights and do not contact other parameters of the model. Yet another is Complete Quantization, where by you quantize both equally the weights and parameters of the product.
Quantization Mindful Schooling
As the title implies, here we quantize the design throughout the education time. Modifications are manufactured to the community just before initial teaching (using dummy quantize nodes) and it learns the 8-bit weights by schooling fairly than heading for conversion later on.
Added benefits and Drawbacks of Quantization
Quantized neural networks, in addition to strengthening performance, appreciably strengthen power performance because of to two aspects: lessen memory entry costs and improved computation efficiency. Lessen-bit quantized info necessitates a lot less info motion on both equally sides of the chip, lessening memory bandwidth and conserving a fantastic offer of strength.
As stated before, it is verified empirically that quantized versions don’t endure from considerable decay. Nonetheless, there are instances when quantization significantly lowers models’ precision. Consequently, with a very good application of article-quantization or quantization-conscious teaching, 1 can prevail over this drop inaccuracy.
Model quantization is vital when it arrives to acquiring and deploying AI designs on edge units that have reduced electric power, memory, and computing. It adds intelligence to the IoT ecosystem effortlessly.
[ad_2]