[ad_1]
In a planet of shifting left, there is a escalating motion: to shift right. I lately attended a panel discussion exactly where the panelists (from tech firms in this house) debated and even insisted – that shifting right will truly let you to deliver a lot more worth to your buyers. Then, as they laid out their arguments, a person detail grew to become distinct: In purchase to change suitable with out considerable threat, you need to have intensive observability of your complete software stack.
Shifting Left vs. Shifting Ideal
1st, what does it suggest to change still left or proper? Well, the shift-remaining movement came out of some thing we have known for lots of several years: if you locate a challenge before, it prices a lot less to deal with it. The strategy is to persuade your developers to do intensive screening, confirm functionality in multiple ranges of pre-generation environments, and capture every difficulty you potentially can right before it goes out to output.
The panel had a simple and obvious argument for shifting suitable: No issue how a great deal testing you do before you release to production, you happen to be usually heading to have dwell bugs. So normalize it. Get folks made use of to swiftly locating and resolving bugs in production. This is identical to the strategy of Chaos Engineering. Bring about troubles “on function” so that the group can get excellent at solving them at 3 pm rather of at 3 am.
Now, I is not going to preach whether or not your workforce ought to shift remaining or change ideal. In fact, as with all matters engineering, it relies upon. There are some issues that should be identified as early as possible – and other individuals that are really hard to come across in decreased environments, just take a significant financial commitment in examination knowledge, and so forth. – but there are also some that can be uncovered and fastened quite speedily with negligible customer disruption in creation. This, mixed with correct release organizing, feature flags, and placing shopper anticipations – means that releasing a bug to generation does not have to be a disaster.
To be thriving at shifting proper, nevertheless, you have to have to be equipped to resolve challenges fast. And to fix problems quick, you will need observability.
To successfully Change Ideal, You Have to have Observability
That is, if you happen to be going to purposefully allow for bugs to enter generation, you have to have to make confident that your groups have the appropriate tools to correct these bugs quickly. So once again, permit me posit: whether you’re intentionally trying to shift proper or you accidentally deployed a bug, do not you want your staff to have all the data they need to have at their fingertips to to start with detect that there is certainly a issue and 2nd to pinpoint particularly where the issue is? Observability does just that.
How Can We Properly Troubleshoot Issues in Creation?
For lots of companies, the course of action of troubleshooting concerns in output is really perplexed nowadays. Functions teams “very own” output methods, but they commonly do not have the nuanced information to truly address generation difficulties. In the best circumstance, the difficulty is a little something that has happened prior to or exists in a runbook, and the operations workforce can remedy it them selves. In the worst case, and in the worst-performing teams, the functions workforce internet pages the on-connect with engineers, who indication on to the simply call, complain about being woken up “for one thing so trivial,” take care of the challenge and go back to sleep with a chip on their shoulder about possessing been woken up in the initial area.
One particular resolution is to have the engineers possess the on-get in touch with rotation – right after all, they are the specialists of the application that is operating in creation. I concur with this in theory, but it is really not generally feasible – from time to time, there are as well many layers or elements of the program, and getting so quite a few persons on-phone is not feasible. Other situations, engineers are not able to truly see output data, at minimum not without the need of large oversight from other groups (assume finance or healthcare industries). Nonetheless other times, with our most effective intentions, no 1 is all over who is an pro on that distinct application – and in a crucial process, we can’t hold out to obtain that person.
My solution, as you could have guessed: observability! There’s additional to it than that, while: give anyone the capacity to debug the method by a conventional hand-off from Engineering to Functions or whatsoever workforce owns the software in output. This hand-off should really consist of almost everything, from what the element becoming deployed does, to inputs and outputs, recognised mistake handling, dependencies, requirements, and so on. From all of these, you can appear up with a watchful observability approach for your application – and at the time you have that, you you should not will need to know the complex enterprise logic of the software in order to troubleshoot quite a few classes of difficulties.
How an Observability Program Helps You Troubleshoot Far more Effectively
Let’s seem at a regular 3-tier application with a caching layer example:
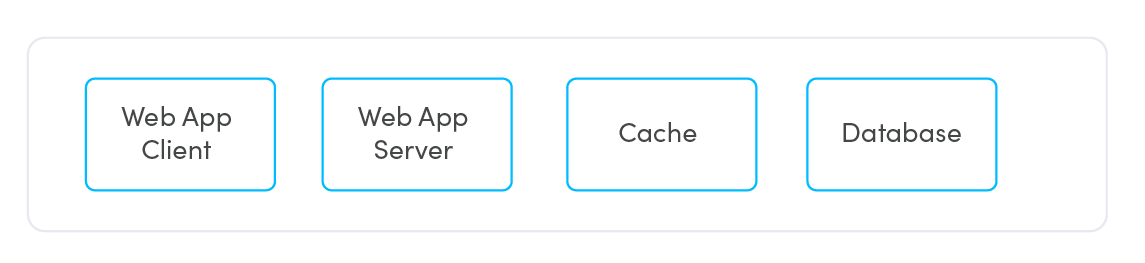
The hand-off details:
- Net App Shopper talks to World-wide-web App Server
- Net Application Server talks to Net App Shopper and the Cache – apart from if it can’t talk to the Cache, it goes to the Databases straight.
- The Cache talks to the Website App Server and the Databases.
There’s much more to the story, of training course. For instance, the precise infrastructure could possibly search like this:
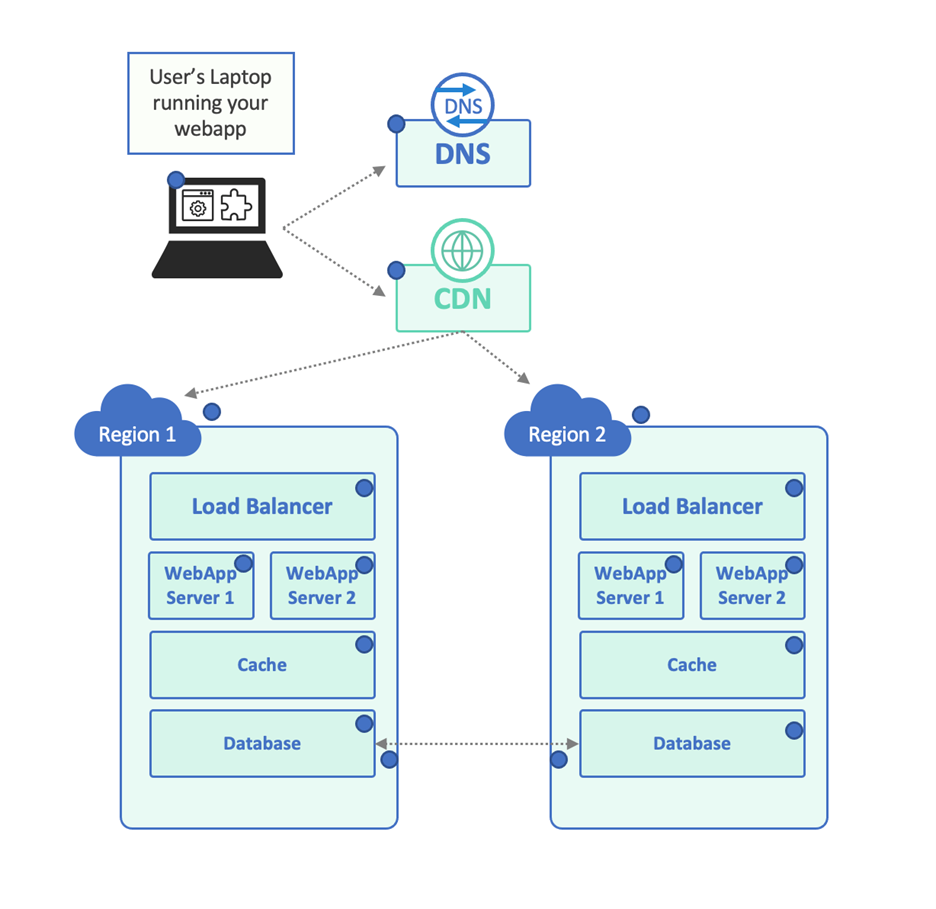
As an apart, it’s attainable that your Engineering crew will not know the variance among this purposeful model and the infrastructure dataflow design – their application may well not get the job done at all when deployed to an natural environment like this – so make positive that infrastructure arranging & evaluation are part of the SDLC, to start out with.
Wanting at the infrastructure diagram, there’s a lot more desired for a profitable hand-off:
- There are customer dependencies on the DNS provider, CDN, and Load Balancer.
- Both the CDN and the load balancer require to persist sessions to the correct Internet Application Server.
- Let’s say the caches are neighborhood, but the databases need to be constant, so they are replicated across the cloud locations.
Example: A Working Observability Strategy
This very simple example is by now having complex – but let’s appear up with an observability method for our application. In the illustration, we included a blue dot to represent each individual checking place:
- We may possibly want to make sure that the client’s atmosphere is doing work effectively – their laptop is ready to execute the customer application, access the DNS server, and so forth. Endpoint Observability or potentially a Actual User Monitoring remedy can support with that.
- We want to make positive that third-get together solutions are performing as required, so perhaps some DNS verification exams and a series of regional CDN exams will assure that they are being adequately balanced in between the different cloud areas. These exact checks can be made use of to make confident the cloud regions by themselves are working, or we can include focused checks for each individual location to make sure.
- For each individual of our server-facet parts, we require to observe inputs and outputs. We can link to the load balancer and make guaranteed it is spreading the load in between the servers. We can make absolutely sure it returns a 200 Ok or even a sample question end result. Exact same factor for each and every specific world-wide-web server. Exact for the cache – we can make certain that it’s up and jogging, but also that the caching performance is doing work properly – potentially query knowledge two times and appear at reaction headers to make certain that it arrived from the cache. Very same for testing the database directly (the response headers should not say that it arrived from the cache).
- We can get as elaborate as we need in this article – most likely the application can return metrics when issued a distinct API contact. We likely want this software to return customized metrics – how prolonged does it get via certain vital locations. We can do it for just about every ask for if the request sends a specific “magic” header, or we can return summary metrics by using an API.
- If the community infrastructure is additional advanced than this, we may want to include some Layer 3-4 (routing, packet-amount) checking.
- At last, given that we know that the Databases need to have to converse to just about every other in buy to synchronize their information, we can set up cross-location checks at the two the community layer and the software layer to make certain there is connectivity and high throughput involving them.
Improved (Observability) Resolution Leads to More rapidly (Incident) Resolution
If we appear at the image over, there are a large amount of blue dots. That’s the place. You will need to have as substantially facts as doable to have comprehensive observability of your application! Remove any of them, and now you’re not really sure where by a prospective problem resides.
To generate the position property, here’s the identical graphic as previously mentioned – but shown in decrease resolution. You just can’t tell what is heading on! That’s what occurs when you only keep track of the application by itself. Maybe you can inform regardless of whether it’s up or down, but you really don’t have any visibility into the details.
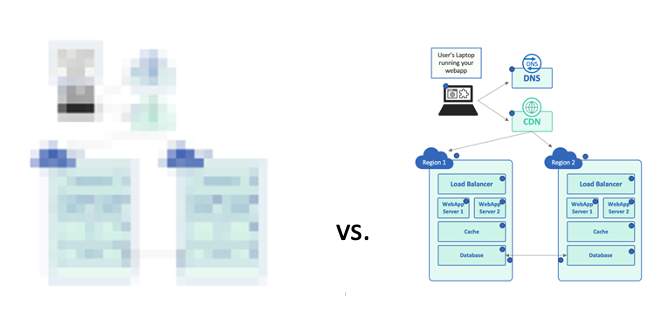
We can continue to keep incorporating additional dots for even greater resolution, but let us glimpse at what we have reached even with this rather basic method:
- By working these checks throughout “normal” periods, we’ve recognized baselines. Now we know how long each component ought to acquire, what its error fee is, etcetera., we can build SLOs for those baselines so that if the efficiency degrades, we’re notified and know specifically what went incorrect.
- If a difficulty happens, we have total 360-degree visibility from the vantage point of the consumer and of the unique infrastructure elements. We can pinpoint an challenge instantly to a individual element.
Suddenly, with a proper hand-off like this, there are less, shorter incident phone calls – and if 1 does need to be escalated to Engineering, the problem has already been narrowed down, so it truly is a great deal faster to fix. If you happen to be heading to change proper, this is the way to do it. If you might be not heading to, you’re however going to have creation concerns – so continue to make positive you have a right engineering hand-off. Everybody included will be happier for the reason that of it.
[ad_2]