[ad_1]
Joins are just one of the most elementary transformations in a usual details processing routine. A Join operator will make it attainable to correlate, enrich and filter across two enter datasets. The two enter datasets are usually categorized as a still left dataset and a ideal dataset based mostly on their putting with respect to the Be a part of clause/operator.
Fundamentally, a Sign up for works on a conditional assertion that involves a boolean expression centered on the comparison concerning a left crucial derived from a history from the remaining dataset and a proper vital derived from a report from the correct dataset. The left and the suitable keys are normally called ‘Sign up for Keys’. The boolean expression is evaluated from each pair of documents throughout the two enter datasets. Primarily based on the boolean output from the evaluation of the expression, the conditional statement contains a range clause to pick possibly a single of the documents from the pair or a merged report of the documents forming the pair.
Carrying out Joins on Skewed Datasets: A Dataset is thought of to be skewed for a Be part of procedure when the distribution of sign up for keys throughout the information in the dataset is skewed toward a smaller subset of keys. For instance when 80
Implications of Skewed Datasets for Be part of: Skewed Datasets, if not managed correctly, can direct to stragglers in the Sign up for stage (Study this linked story to know additional about Stragglers). This delivers down the all round execution performance of the Spark task. Also, skewed datasets can trigger memory overruns on specific executors leading to the failure of the Spark work. As a result, it is vital to recognize and deal with Be part of-based stages where by substantial skewed datasets are concerned.
Approaches to Deal with Skewed Joins: Until finally now you ought to have observed a lot of scattered literature to take care of skewed Joins but most of these emphasize 1 or 2 techniques and describe briefly the particulars and restrictions included. Taking into consideration this scattered description, this distinct tale is an try to present you with a finish and detailed list of five significant methods to handle skewed Joins in each achievable circumstance:
Broadcast Hash Join
In ‘Broadcast Hash’ be part of, either the left or the correct input dataset is broadcasted to the executor. ‘Broadcast Hash’ be a part of is immune to skewed input dataset(s). This is thanks to the point that partitioning, in accordance with ‘Join Keys’, is not obligatory on the still left and the ideal dataset. Listed here, a person of the datasets is broadcasted even though the other can be properly partitioned in a ideal way to achieve uniform parallelism of any scale.
Spark selects ‘Broadcast Hash Be part of’ based on the Sign up for kind and the size of the input dataset(s). If the Join type is favorable and the dimensions of the dataset to be broadcasted stays down below a configurable limit (spark.sql.autoBroadcastJoinThreshold (default 10 MB)), ‘Broadcast Hash Join’ is chosen for executing Sign up for. For that reason, if you boost the restrict of ‘spark.sql.autoBroadcastJoinThreshold’ to a better worth so that ‘Broadcast Hash Be part of’ is picked only.
One particular can also use broadcast hints in the SQL queries on both of the input datasets primarily based on the Join style to force Spark to use ‘Broadcast Hash Join’ irrespective of ‘spark.sql.autoBroadcastJoinThreshold’ price.
Therefore, if 1 could pay for memory for the executors, ‘Broadcast Hash’ join should really be adopted for more quickly execution of skewed sign up for. Having said that here are some salient factors that need to have to be thought of though planning to use this speediest method:
- Not Applicable for Entire Outer Be a part of.
- For Interior Be a part of, executor memory should accommodate at the very least a smaller of the two input datasets.
- For Remaining, Left Anti, and Left Semi Join, executor memory ought to accommodate the correct enter dataset as the right just one needs to be broadcasted.
- For Appropriate, Suitable Anti, and Right Semi Joins, executor memory ought to accommodate the left input dataset as the remaining just one desires to be broadcasted.
- There is also a significant demand for execution memory on executors primarily based on the measurement of the broadcasted dataset.
Iterative Broadcast Sign up for
‘Iterative Broadcast’ strategy is an adaption of the ‘Broadcast Hash’ be a part of in buy to handle much larger skewed datasets. It is valuable in predicaments the place possibly of the input datasets can not be broadcasted to executors. This might materialize because of to the constraints on the executor memory boundaries.
In buy to offer with such scenarios, the ‘Iterative Broadcast’ system breaks downs just one of the input information sets (ideally the smaller sized one particular) into one or lesser chunks thereby guaranteeing that each individual of the resulting chunks can be effortlessly broadcasted. These more compact chunks are then joined one by a single with the other unbroken input dataset utilizing the conventional ‘Broadcast Hash’ Be part of. Outputs from these various joins are last but not least combined together making use of the ‘Union’ operator to produce the final output.
One particular of the techniques in which a Dataset can be broken into more compact chunks is to assign a random selection out of the preferred range of chunks to every single record of the Dataset in a newly extra column, ‘chunkId’. Once this new column is completely ready, a for loop is initiated to iterate on chunk quantities. For every iteration, for starters the documents are filtered on the ‘chunkId’ column corresponding to the recent iteration chunk number. The filtered dataset, in every iteration, is then joined with the unbroken other enter dataset applying the standard ‘Broadcast Hash’ Be a part of to get the partial joined output. The partial joined output is then merged with the past partial joined output. Just after the loop is exited, one particular would get the overall output of the be a part of procedure of the two original datasets. This method is shown down below in Determine 1.
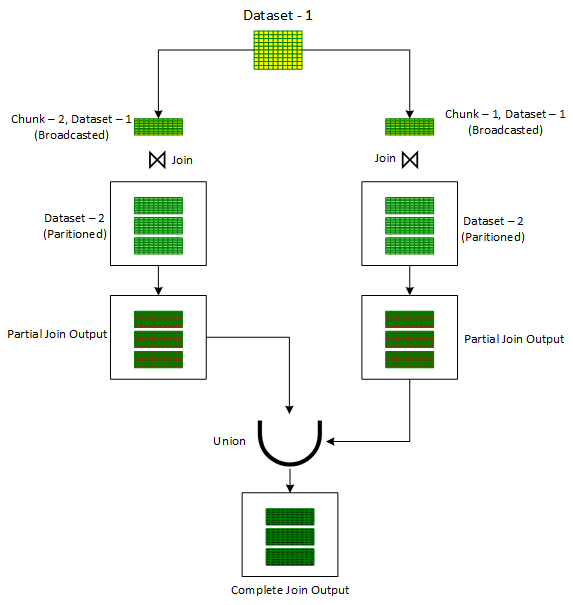
However, in contrast to ‘Broadcast Hash Join’, ‘Iterative Broadcast Join’ is confined to ‘Inner Joins’ only. It can not take care of Comprehensive Outer Joins, Still left Joins and Appropriate Joins. On the other hand, for ‘Inner Joins’, it can deal with skewness on each the datasets.
Salted Type Merge Be a part of
‘Sort Merge’ method is quite robust in dealing with Joins in circumstance of useful resource constraints. Extending the identical, the salted version of ‘Sort Merge ’ can be used incredibly successfully when one particular would like to be a part of a big skewed dataset with a lesser non-skewed dataset but there are constraints on the executor’s memory.
Moreover, the Salted Form Merge variation can also be utilized to conduct Left Sign up for of scaled-down non-skewed datasets with the larger skewed dataset which is not feasible with Broadcast Hash Sign up for even when the lesser dataset can be broadcasted to executors. However, to make absolutely sure that Sort Merge Be part of is selected by Spark, one has to change off the ‘Broadcast Hash Join’ method. This can be carried out by location ‘spark.sql.autoBroadcastJoinThreshold’ to -1.
The working of ‘Salted Form Merge’ Be part of is sort of very similar to ‘Iterative Broadcast Hash’ Be a part of. An more column ‘salt key’ is released in 1 of the skewed enter datasets. Just after this, for every record, a quantity is randomly assigned from a picked vary of salt crucial values for the ‘salt key’ column.
Immediately after salting the skewed input dataset, a loop is initiated on salt important values in the selected vary. For every single salt essential benefit staying iterated in the loop, the salted input dataset is first filtered for the iterated salt vital-price, following filtration, the salted filtered enter dataset is joined alongside one another with the other unsalted input dataset to generate a partial joined output. To make the final joined output, all the partially joined outputs are mixed alongside one another applying the Union operator.
An substitute tactic also exists for the ‘Salted Type Merge’ technique. In this, for each salt crucial worth being iterated in the loop, the second non-skewed input dataset is enriched with the current iterated salt important benefit by repeating the exact same benefit in the new ‘salt’ column to deliver a partial salt enriched dataset. All these partial enriched datasets are merged using the ‘Union’ operator to make a combined salt enriched dataset edition of the 2nd non-skewed dataset. Immediately after this, the initially skewed salted dataset is Joined with the next salt enriched dataset to generate the closing joined output. This approach is shown down below in Figure 2:
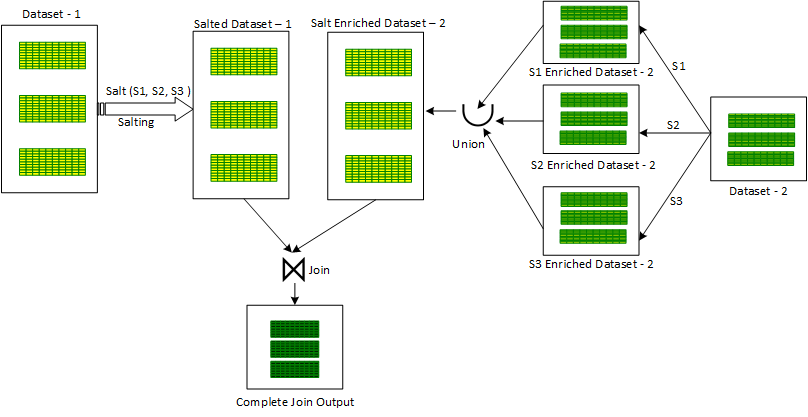
Salted Type Merge Sign up for are not able to cope with Whole Outer Be a part of. Also, it are unable to take care of skewness on both equally the input dataset. It can deal with skew only in the remaining dataset in the Remaining Joins class (Outer, Semi and Anti). In the same way, it can tackle skew only in the proper dataset in the Right Joins category.
AQE (Highly developed Query Execution)
AQE is a suite of runtime optimization capabilities that is now enabled by default from Spark 3.. 1 of the essential options of this suite pack is the functionality to quickly enhance Joins for skewed Datasets.
AQE performs this optimization normally for ‘Sort Merge Joins’ of a skewed dataset with a non- skewed dataset. AQE operates at the partitioning move of a Kind Merge Be part of in which the two input Datasets are to start with partitioned primarily based on the corresponding Be a part of Critical. Following the shuffle blocks are created by the MapTasks during partitioning, Spark Execution Motor will get stats on the dimensions of every shuffled partition. With these stats readily available from Spark Execution Motor, AQE can identify, in tandem with sure configurable parameters, if certain partitions are skewed or not. In situation certain partitions are located as skewed, AQE breaks down these partitions into scaled-down partitions. This breakdown is managed by a established of configurable parameters. The smaller sized partitions ensuing from the breakdown of a greater skewed partition are then joined with a duplicate of the corresponding partition of the other non-skewed input dataset. The method is shown below in Determine
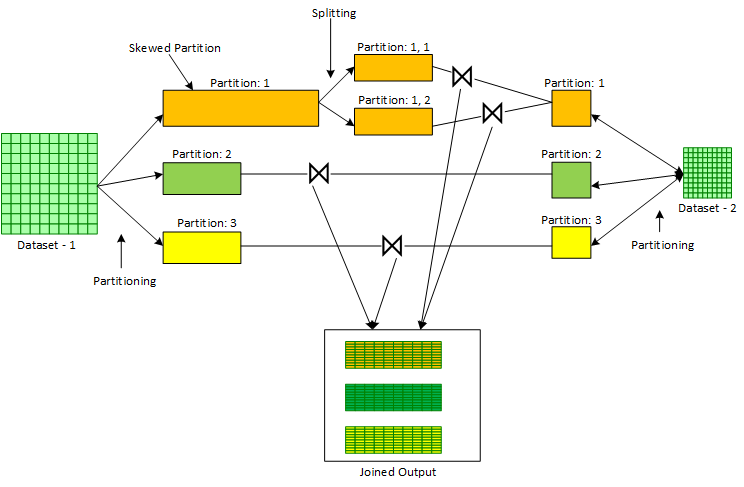
Pursuing are the config parameters that have an affect on the skewed sign up for optimization feature in AQE:
“spark.sql.adaptive.skewJoin.enabled”: This boolean parameter controls whether or not skewed be part of optimization is turned on or off. The default value is real.
“spark.sql.adaptive.skewJoin.skewedPartitionFactor”: This integer parameter controls the interpretation of a skewed partition. The default worth is 5.
“spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes”: This parameter in MBs also controls the interpretation of a skewed partition. The default benefit is 256 MB.
A partition is regarded skewed when both of those (partition measurement > skewedPartitionFactor * median partition dimensions) and (partition dimension > skewedPartitionThresholdInBytes) are real.
AQE like ‘Broadcast Hash Join’ and ‘Salted Form Merge Join’ simply cannot take care of ‘Full Outer Join’. Also, it can’t tackle skewedness on each the input dataset. Consequently, as in case of ‘Salted Sorted Merge Join’, AQE can manage skew only in the still left dataset in the Left Joins category (Outer, Semi and Anti) and skew in the proper dataset in the Appropriate Joins group.
Broadcast MapPartitions Join
‘Broadcast MapPartitions Join’ is the only system to fasten a skewed ‘Full Outer Join’ between a substantial skewed dataset and a lesser non-skewed dataset. In this approach, the more compact of the two input datasets are broadcasted to executors even though the Sign up for logic is manually provisioned in the ‘MapPartitions’ transformation which is invoked on the larger sized non-broadcasted dataset.
Whilst ‘Broadcast MapPartitions Join’ supports all type of Joins and can take care of skew in both or both of the dataset, the only limitation is that it necessitates sizeable memory on executors. The larger executor memory is demanded to broadcast just one of the smaller enter dataset, and to assistance intermediate in-memory selection for manual Be part of provision.
I hope the above blog has provided you a excellent viewpoint on managing skewed Joins in your Spark programs. With this history, I would motivate you all to investigate a single of these alternatives each time you come upon stragglers or memory overruns in the Be a part of phases of your Spark apps.
In case you would like to have code snippets related to each and every of these approaches, you could achieve out to me on LinkedIn.
[ad_2]