The data model in Cassandra is different from RDBMS in many ways. A Cassandra Data Model contains the following elements:
Cluster:
A Cluster in Cassandra is the outermost container of the database. It contains one or more data centres. A data centre again acts as a collection of related nodes. With four nodes in a cluster, Cassandra facilitates replication as each node has a copy of the same data. If any of the four nodes are not working then the purpose can still be served by the other three nodes on request. Cassandra facilitates an increase in the number of nodes in the cluster which thus advances the throughput.
Keyspace:
A keyspace in Cassandra is the outermost container for data. A Keyspace in Cassandra has some basic attributes, including,
- Replication factor: It is used to define the number of the machine in the cluster which will be used in replication, i.e, the number of machines receiving the copies of the same data.
- Replica placement Strategy: The Replica Placement Strategy in Cassandra is used to specify the way to place the replicas in the ring. The strategy can be of three types: Simple strategy (rack-aware strategy), old network topology strategy (rack-aware strategy) and network topology strategy (datacenter-shared strategy)
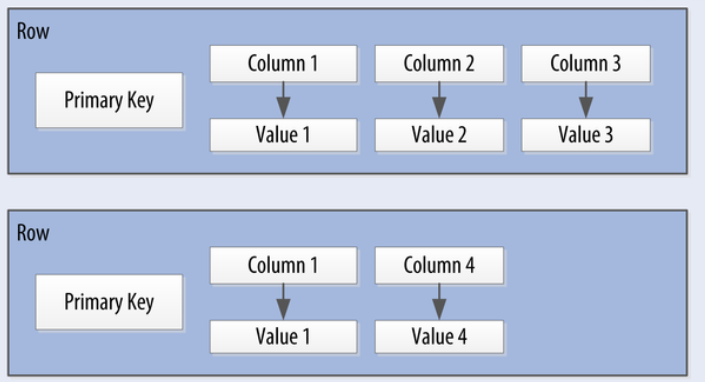
Column families:
A keyspace in Cassandra holds a list of one or more column families. A column family in Cassandra holds a collection of rows, where each row contains ordered columns.
Cassandra data Models Rules:
While modelling data in Cassandra, the following rules must be kept in mind:
- JOINS, GROUP BY, OR clause, aggregation etc. are not supported. The data thus needs to be stored in a way so that it can be easily retrieved whenever needed.
- For better read performance and data availability, the writes need to be maximized, since the Cassandra is optimized for high write performances.
- By maximizing the number of data writes, the data read performance can also be optimized, as there is a trade off between data write and data read in Cassandra.
- Cassandra is a distributed database. A maximization in data duplication provides instant data availability with maximized fault tolerance.
Data Modeling Goals:
While modelling data in Cassandra, the following goals must be kept in mind:
To spread an equal amount of data on each node of the Cassandra cluster:
Choose integers as a primary key. Based on partition keys the data will spread to different nodes. The partition keys are the first part of the primary key.
To minimize the number of partitions read while querying data:
To bind a group of record, partition keys are used. Data are collected from different nodes present in different partitions when the read query is issued.