[ad_1]
You could not have listened to the phrase data downtime, but I’m eager to guess you’ve skilled it and the value of poor information firsthand.
Urgent ping from your CEO about “missing data” in a essential report? Duplicate tables wreaking havoc in your Snowflake warehouse, all titled some variation of “Mikes_Desk_Very good-V3.”? Or, probably you have unintentionally created a choice based on terrible facts from very last year’s forecasts?
Knowledge downtime is when data is lacking, faulty, or normally inaccurate. It intentionally recalls the early phases of the internet when sites would go down with what right now would be alarming frequency.
It can make feeling now, searching back on it. Not only ended up there infrastructure problems, but not that quite a few men and women have been making use of the internet, and sites were not approximately as valuable. As that altered with the increase of the cloud, e-commerce, and SaaS, making sure reliability became mission-crucial to a enterprise, and site trustworthiness engineering (SRE) was born.
Details is at a similar minute in time. Technologies are advancing, companies are shifting to the cloud, and details is starting to be much more prevalent and precious than ever right before.
The corollary to this is that as information gets to be much more useful, the effects of poor data high-quality come to be extra extreme. The ideal methods, systems, and investments that ended up sufficient just a yr or two in the past will now jeopardize an organization’s means to contend.
By 2025, 8
In this post, we will protect 8 reasons why the expense of terrible knowledge is rising. Let us get into it.
Info Is Going Downstream
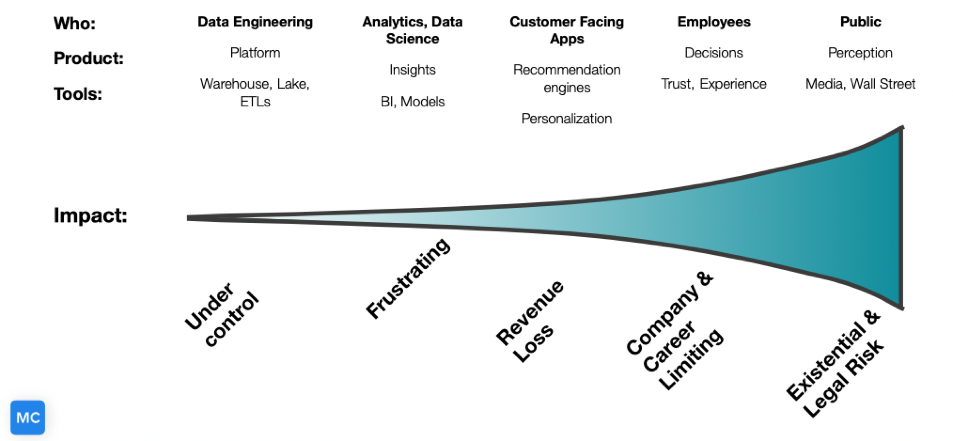
Each stage also acts as a filter preventing bad details from relocating downstream. The obstacle is there are numerous tendencies in info at the moment that are accelerating the rate of knowledge shifting downstream from knowledge democratization, info solutions, reverse ETL, and much more.
Details Stacks Are Getting Far more Intricate
The further more downstream that lousy knowledge travels, the far more pricey the correct. It is significantly simpler and quicker to have a information engineer troubleshoot an ETL pipeline than for a info scientist to re-educate a machine mastering product that has been fed bad details.
It’s not just the remediation that is high-priced possibly. As corporations increasingly rely on complicated data property to enable execute business enterprise selections, the opportunity fees of bad data increase as perfectly.
For instance, I spoke with an financial investment firm with a equipment studying product that would obtain bonds automatically when they satisfied certain criteria. Schema problems would get the model offline for days or weeks and, as a consequence, ground this element of their small business to a standstill. Yikes.
As data stacks come to be extra complicated, there are also far more info “handoffs,” introducing the option for extra problems. For illustration, just one gaming enterprise I spoke with recognized a drift in their new consumer acquisition data.
The social media system they had been promotion on changed their knowledge routine, so they have been offering data each and every 12 several hours rather of 24. The company’s ETLs ended up established to decide on up information only at the time for every day, so this meant that quickly half of the campaign facts that was remaining despatched to them wasn’t finding processed or handed downstream, skewing their new person metrics absent from “paid” and in the direction of “organic.”
Enhanced Knowledge Adoption

In accordance to a Google Cloud and Harvard Small business Review report, 9
This is an brilliant pattern. Nonetheless, much more details consumers and a lot more information analysts necessarily mean much more individuals sitting down on their hands when data downtime strikes.
Anticipations of Knowledge Customers Are Escalating
And they have better expectations than at any time. They are accustomed to leveraging SaaS merchandise that are guaranteeing 5 9’s of availability, meaning they are down a lot less than 12 minutes a 12 months. Actually, I don’t know any details groups clearing that bar.
Sadly, most facts groups are evaluated based on a experience. Either information shoppers and executive management “feel” the group is executing well or improperly. That’s simply because virtually 6
With substantial information consumer expectations and very little qualitative information measuring overall performance, knowledge downtime has intense repercussions not just for businesses but for data groups as perfectly.
Information Engineers Are More difficult to Locate

This is not just anecdotal evidence both. The Dice 2020 Tech Position Report said details engineer was the swiftest-growing position in technologies with a 5
Facts engineers are rapidly getting one particular of the most important property. Getting them offline to repair downtime is high-priced, and carrying out it continuously hazards them deciding to go away to wherever they will get the job done on much more appealing initiatives.
Data Top quality Tasks Are Starting to be Dispersed
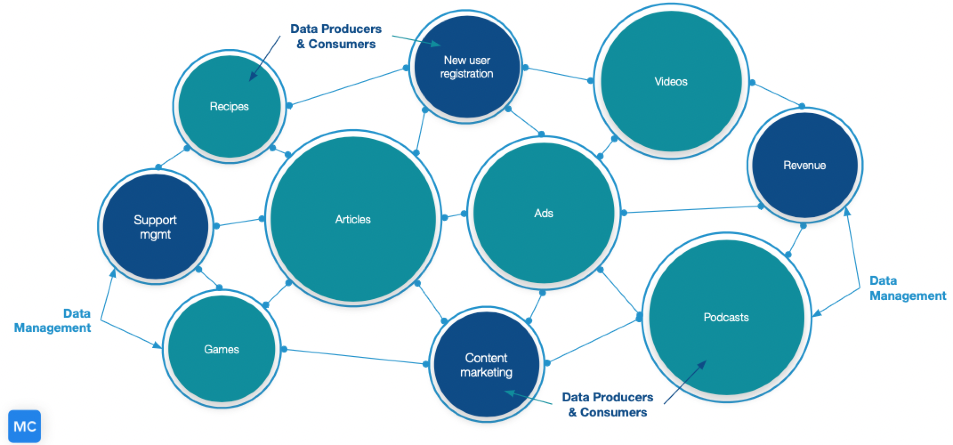
This has the advantage of bringing data groups closer to the company and being familiar with the objective of all relevant data operations on the other hand, by its really character also diffuses obligation.
A decentralized set up places a greater burden on obvious interaction and crisp processes. There is not 1 inbox or Slack channel to frantically ping when items are heading incorrect, and that’s scary.
Devoid of strong procedures, the diffusion of obligation can extend the time it will take to solve poor knowledge or information downtime when these issues cross domains.
Crumbling of the Cookie
Companies are likely to turn into much more reliant on initial as opposed to third-occasion information as a outcome of tightening polices such as GDPR and the industry’s transfer away from the cookie.
That usually means they will require to accumulate more data, which will develop into extra beneficial considering the fact that they can no extended rely on Google algorithms to assistance their advertisements uncover the suitable individuals. Therefore, info downtime is starting up to have a much larger effect on advertising and marketing functions, and the price of poor facts is increasing.
Knowledge Is Getting to be a Item, and It’s Super Aggressive
Info teams are creating sophisticated data items that are swiftly starting to be aspect of the shopper offering and unlocking new value for their providers.
In some industries, this has come to be super competitive. If your workforce is not generating actionable insights, you will speedily get outperformed by an individual who is.
I see this most frequently in the media space, where info has come to be a full arms race. The scale of data groups and the financial commitment in them is astronomical. It has been spectacular to check out these organizations transfer from hourly batching to 15 minutes, to each 5 minutes, and now setting up to stream.
There is no place for undesirable facts in this setting. Throughout your details downtime, anyone else is publishing the scoop, acquiring clicks, and getting worthwhile insights into their viewers.
An Ounce of Treatment method Is Worth a Pound of Suffering
When you consider the growing price of lousy information and that most businesses have far more data excellent concerns than they believe, growing your financial investment in data top quality or information observability seems like a smart go to make.
Some facts groups are incredibly perceptive when it comes to interior indicators that it’s time to spend in details quality (from migrating to a cloud info warehouse like Snowflake or Redshift to having the CEO yell), but exterior motorists like the kinds talked about previously mentioned can get dropped in the shuffle.
I advise using a proactive approach. Think about how you can commit in your people, processes, and technologies to mitigate the mounting charge of terrible knowledge.
[ad_2]